
Often, when we hear about Java serialization, we find resources or challenges that only talk about generating and executing ysoserial payloads.
In some situations, this can work. However, as soon as a customer is aware of this possibility, rather than using a more secure format, they generally prefer to use a library such as notsoserial which prevents the deserialization of unauthorized classes.
And if the use of interesting classes is blocked, then we’re stuck with a classic API that uses Java serialized objects rather than a more common format such as JSON.
This means we can run tests just as we would with a normal API, doesn’t it? Technically, yes, but it’s not a simple task. JSON objects can be rewritten by humans and we can also read them easily, which is not the case with Java serialized objects since they are in binary format.
Analysis of a Java serialized Object
During a web application pentest, we had to analyse a serialised object. To do this, we opted to use tools such as SerializationDumper to transform the stream into a more readable verbose format.
Now that we can analyse the data, we may find an interesting string in it. The tool also allows us to reconstruct the stream from the readable format, which means we can patch values into it – how cool is that?
Yes… but not really. In fact, if an application doesn’t use many serialized messages, it’s possible to do this process manually despite the sometimes long time needed to extract the serialized stream, run the tools on it, rebuild the stream and insert it back into a request. However, when the application uses them for each message, it becomes very time-consuming.
Developing a Burp Extension
To make our work easier, the first step is automation. We started by creating a Burp extension that integrates a modified version of SerializationDumper. The modified version is interesting because it can be used as a library, which avoids having to write a wrapper around a program that we have to call every time we want to do something.
Unfortunately, the modified version doesn’t seem to support the reconstruction of Java streams and, even if we implement it, we think the format is still too verbose for us to work with. So we’ve decided to redevelop everything with these concerns in mind.
We’re pleased to announce the release of one of our in-house tools: Java Serde.
This tool is used when we need to interact with serialized Java objects because it makes them easier to manipulate. The idea is to convert a stream of objects into a JSON document and vice versa. This makes it easier to identify the shape of objects and also to forge new objects.
We chose to use JSON rather than a custom human-readable format because it integrates well with many of the existing tools used to manipulate JSON documents.
Demonstration of Java Serde
o illustrate how our tool works, we’ll take a few examples from online resources, including PortSwigger’s challenges, which we risk revealing a little. To avoid any spoilers, we recommend that you do them yourself first.
Reading from a stream
When authenticating on one of the PortSwigger challenges, we receive a session cookie that contains a Base64 encoded Java stream.

If we decode the cookie, we obtain a raw Java stream which is not easy to manipulate. We can’t easily modify the length of the strings and we have few information on the shape of the object. But with our tool we can transform the binary into a JSON document.
$ echo "rO0A[…]cg==" | base64 -d | java -jar java-serde.jar decode
[
{
"@handle": 8257538,
"@class": {
"@handle": 8257536,
"@name": "lab.actions.common.serializable.AccessTokenUser",
"@serial": 1824517384844061057,
"@flags": 2,
"@fields": [
{
"@name": "accessToken",
"@type": "Ljava/lang/String;"
},
{
"@name": "username",
"@type": "Ljava/lang/String;"
}
],
"@annotations": [],
"@super": null
},
"@data": [
{
"@values": [
"fi9b2c76gn4pix5wfxadcxp2lbv6j35j",
"wiener"
],
"@annotations": []
}
]
}
]As we can see, there’s a lot of data but we have at least one JSON. The idea is to keep a lot of information about the original stream to make it easier to rebuild, but this makes it more verbose.
The first field we can see is ‘handle’. This is a number assigned to elements that can be referenced later in the feed. When you edit them, you can select any number, and our program will take care of using the correct one when writing the stream.
Next, we can easily identify that there is a class called ‘AccessTokenUser’ and its fields, ‘username’ and ‘accessToken’, which are both strings.
Finally, we can see the values of each field in the order they are declared in the class description (this is something that could change in the future, with a key-value object to make things easier to read and write).
Unfortunately, the challenge doesn’t ask us to modify the object (like changing the username).
Patching a stream
Imagine you’re playing a game found on GitHub that uses Java objects for its save format and you’re not very patient or good at the game.
You can modify the save file to give you what you want.
We found a little game on GitHub: an RPG inspired by Zelda.
When we launch the game, we see our character, our health points and our money (we also see each hitbox, but that’s a detail). After hitting a few enemies, we’ve only got 2 hearts left and we’ve found 5 rubies.

We can now use our programme to modify our backup file to restore our health and get some pocket money.
$ cat Zelda.ser | java -jar java-serde.jar decode
[
{
"@handle": 8257538,
"@class": {
"@handle": 8257536,
"@name": "zelda.engine.SaveData",
"@serial": 40658369698633593,
"@flags": 2,
"@fields": [
{
"@name": "health",
"@type": "I"
},
{
"@name": "rupee",
"@type": "I"
},
{
"@name": "sceneName",
"@type": "Ljava/lang/String;"
}
],
"@annotations": [],
"@super": null
},
"@data": [
{
"@values": [
2,
5,
"ForrestScene"
],
"@annotations": []
}
]
}
]We can see here that the save format is simple, with just three specific pieces of information about the game: the player’s health, rubies and position.
You can use the jq command to modify JSON easily.
$ cat Zelda.ser | java -jar java-serde.jar decode | jq '.[0]."@data"[0]."@values" = [5, 69009, "CastleScene"]' > Zelda.json
$ cat Zelda.json | java -jar java-serde.jar encode > Zelda.serThen, if we restart the game, we can see our changes.
Client and server exchanges
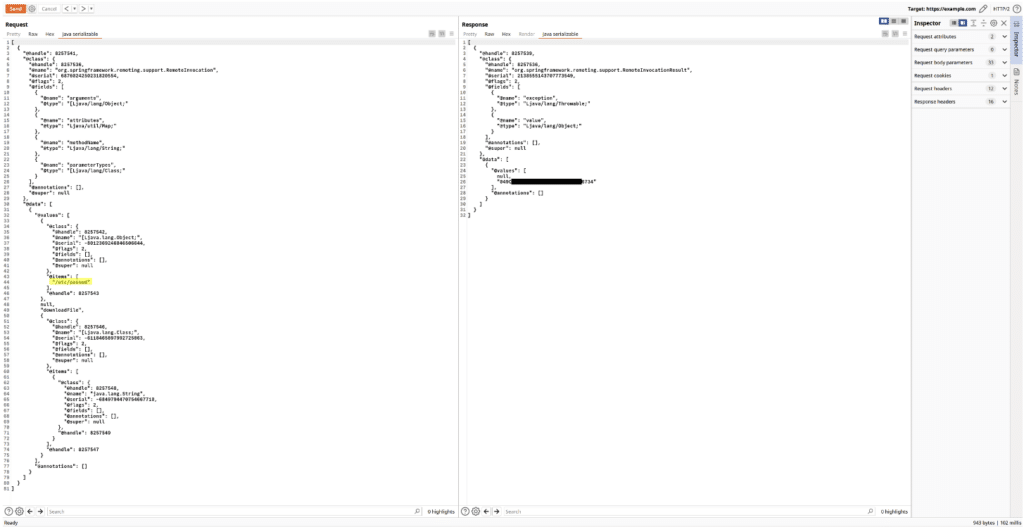
During a web pentest, we tested a web application and a rich client, both written in Java. For each message sent between these two applications, a Java serialized object was also sent.
During our tests, we discovered an interesting request to the server. The client would send a path and the server would respond with a token that could be used to download the file to the given path.
Using our program as a Burp extension, it was possible to easily patch the stream in the request and extract the token from the response.
The development of the extension has enabled us to identify even more vulnerabilities and to be more effective in exploiting them.
Conclusion
As we have written the program for a specific use case, some parts of the specification are not implemented and may be in the future if we encounter this case.
The Burp extension also requires the stream to be in a specific location and with a specific encoding, you can always patch the code to extract the data from the correct location.
For example, it is not possible to represent the same character string in a stream with two different handles; in our program, we merge these references. This can create unexpected differences when re-encoding a stream.
In any case, we sometimes find basic vulnerabilities that are difficult to exploit because we can’t manipulate the data easily, and for them to be fixed we have to demonstrate the vulnerability. We hope that this extension will make it easier for other pentesters to demonstrate issues.
Author: Arnaud PASCAL – Pentester @Vaadata