
Les APIs sont partout. Dans la plupart des systèmes informatiques (applications mobiles, plateformes web, infrastructures cloud, etc.) et dans tous les secteurs d’activité, ces interfaces de programmation facilitent les échanges de données et leur mise à disposition à un public large, qu’il s’agisse de clients, de partenaires ou de collaborateurs. Les APIs sont également le moteur de développement et de croissance des objets connectés car elles constituent le socle des canaux de communication des systèmes IoT.
En 2019, une étude publiée par la société Akamai estimait que 83 % de l’ensemble du trafic web était généré par des APIs. Cette tendance se confirme car les APIs sont devenues le moyen le plus simple d’exposer les fonctionnalités et les données d’un système d’information.
Cependant, si la diffusion des APIs est à l’origine d’applications toujours plus sophistiquées qui améliorent les usages et la performance des entreprises, elle entraîne également une forte augmentation du risque cyber. En effet, leur exposition et leur caractère « critique » – dû au fait qu’elles manipulent des données sensibles – en font des cibles de choix pour les cyberattaques. La sécurité des APIs doit donc être centrale dans une stratégie cybersécurité.
Pourquoi la sécurité des APIs est-elle importante ?
Les attaques ciblant les APIs sont l’une des menaces de sécurité les plus graves auxquelles les entreprises sont confrontées, car elles fournissent des accès directs à des données et des fonctionnalités sensibles. Et les attaquants ont pris conscience de la prévalence des APIs et de l’existence de vulnérabilités critiques dans ces interfaces. Le problème est que les applications web restent la cible principale des attaques (90% selon Verizon *) et que les APIs représentent désormais 90% de la surface d’attaque des applications web. Ainsi, les APIs sont devenues un des principaux vecteurs d’attaque, avec des conséquences financières désastreuses pour les entreprises qui en font les frais.
Par ailleurs, étant donné que les APIs utilisent des technologies Web, un développeur d’API sera confronté aux vulnérabilités courantes de cet écosystème. La plupart des risques inhérents aux applications web sont applicables aux APIs, mais en raison de leur nature, elles étendent la surface d’attaque et sont confrontées à des facteurs de risque uniques. Alors que les applications web sont conçues pour donner accès à une interface utilisateur spécifique et exposer une fonctionnalité précise à partir du back-end, les APIs fournissent un canal beaucoup plus flexible vers le back-end, en termes de quantité d’informations récupérables sur les serveurs. En effet, les APIs facilitent le transfert de grandes quantités de données, bien plus aisément que ne le permettent les applications web.
Une API peut être appelée à plusieurs reprises pour générer une attaque DoS. De plus, les firewalls, antivirus et autres solutions techniques de sécurité ne peuvent pas bloquer les attaques qui exploitent certaines vulnérabilités spécifiques aux APIs. Ils ne peuvent pas détecter les attaques par injection, ni les attaques logiques sur les paramètres ou sur les workflows. De même, les scanners de vulnérabilités utilisés pour des audits de sécurité automatisés ne peuvent pas identifier la plupart de ces vulnérabilités – et particulièrement les failles logiques « TRÈS » répandues dans les APIs, à la différence des tests d’intrusion qui suivent une méthodologie éprouvée intégrant une phase d’exploitation des vulnérabilités « TRÈS » précieuse, permettant non seulement d’identifier d’autres failles mais également d’en mesurer les impacts et les effets de bords potentiels.
La sécurité doit donc être un élément essentiel de la stratégie de développement d’API de toute organisation. L’objectif de cet article, qui ne vise pas l’exhaustivité, est de vous présenter les bonnes pratiques permettant de sécuriser vos APIs, et d’expliciter les vulnérabilités courantes exploitées par des attaquants malveillants pour les compromettre. Nous illustrerons certains des risques via des cas concrets rencontrés lors de nos tests d’intrusion sur des APIs.
Mais avant d’entrer dans le vif du sujet, quelques précisions sur les différences et spécificités des principaux types d’APIs utilisés aujourd’hui.
API REST, SOAP & GraphQL : quelles sont les différences et spécificités de ces principaux types d’APIs ?
Les APIs sont des interfaces qui échangent des commandes et des données, ce qui nécessite des protocoles et des architectures clairs. Aujourd’hui, il existe 3 principaux types d’APIs : REST, SOAP et GraphQL, chacune présentant des caractéristiques spécifiques.
Caractéristiques des APIs REST
L’architecture REST (representational state transfer) est l’approche la plus courante pour construire des APIs. REST s’appuie sur une relation client-serveur qui sépare les parties front et back-end de l’API et offre une grande flexibilité en matière de développement et de mise en œuvre. REST est sans état (stateless), ce qui signifie que l’API ne stocke aucun état ou donnée entre les requêtes.
Les APIs REST sont basées sur le protocole HTTP et prennent en charge le chiffrement TLS. Le protocole TLS (sur lequel nous reviendrons plus loin dans cet article) permet de garder une connexion privée et de vérifier que les données échangées entre deux systèmes (un serveur et un serveur, ou un serveur et un client) sont chiffrées et non lisibles en cas d’attaque Man In The Middle.
Les APIs REST utilisent également le format de fichier JSON (JavaScript Object Notation), qui facilite le transfert des données via les navigateurs web.
API et protocole SOAP
Le protocole SOAP est une norme de messagerie définie par le World Wide Web Consortium (W3C) et utilisée pour créer des APIs écrites en XML. SOAP prend en charge un large éventail de protocoles de communication, tels que HTTP, SMTP et TCP.
L’approche SOAP, par le biais de l’IDL Web Services Description Language (WSDL), détermine la manière dont un message est traité, les fonctionnalités et les modules inclus, le ou les protocoles de communication pris en charge.
Contrairement à REST, SOAP est une norme très structurée, étroitement contrôlée et clairement définie. Par exemple, les messages SOAP peuvent contenir jusqu’à quatre composants, dont une enveloppe, un en-tête, un corps et un défaut (pour le traitement des erreurs). De plus, les APIs SOAP utilisent des protocoles intégrés connus sous le nom de WS Security (Web Services Security). Ces protocoles définissent un ensemble de règles qui permettent d’ajouter un mécanisme de confidentialité et d’authentification (chiffrement et signatures XML, jetons SAML, etc.).
Les APIs GraphQL
GraphQL est un langage de requête et un environnement d’exécution développé comme une alternative à l’architecture REST. En effet, les APIs GraphQL disposent de leur propre architecture basée sur un système de schéma de requêtes.
Quelles sont les vulnérabilités courantes des APIs et comment se protéger ?
Manque de Rate limiting, attaques DoS et attaques brute force sur les APIs
Principe et fonctionnement des attaques DoS
Un déni de service (Denial of Service ou DoS) est une attaque réalisée dans le but de rendre indisponible les services. En effet, une attaque DoS fonctionne en épuisant une ressource limitée dont une API a besoin pour répondre aux demandes légitimes. En inondant une API de fausses requêtes, ses ressources sont bloquées pour répondre à ces requêtes et pas aux autres.
L’objectif des attaques DoS n’est pas d’altérer, de supprimer ni de voler des données. L’objectif est tout simplement de nuire au fonctionnement d’un service web ou à la réputation d’une entreprise offrant ce type de services.
Ainsi, les entreprises dont la principale activité est basée sur un flux d’information sur le web (via une API ou tout autre service web) sont menacées, et susceptibles d’être paralysées à tout moment. Par ailleurs, les acteurs malveillants utilisent les attaques DoS comme arme pour exercer un chantage envers les entreprises. Le message est clair : une rançon est demandée en échange de la « non-paralysie » de leur activité. Il est évident que le ralentissement, voire le blocage de leurs services pendant quelques minutes pourrait occasionner des pertes financières importantes, et altérer la confiance des utilisateurs. Il est donc nécessaire de trouver des parades pour s’en protéger, notamment la vérification des requêtes, la surveillance du trafic, l’implémentation de règles et de seuils (Rate Limiting – que nous détaillons un peu plus loin dans cet article), etc.
De même, lors d’un pentest d’API ou d’application web, vous pouvez inclure des tests DoS, afin d’évaluer la résistance de vos services face à ce type d’attaque.
Attaques brute force sur des APIs
Dans une attaque brute force, un attaquant utilise des outils pour envoyer un flux continu de requêtes à une application ou une API – afin de tester toutes les combinaisons possibles d’un paramètre, via un processus d’essais et d’erreurs pour espérer deviner juste. Les objectifs peuvent être multiples : brute force d’un formulaire d’authentification afin de voler un compte, brute force d’un identifiant pour récupérer des données sensibles, brute force d’un secret, etc.
C’est une méthode d’attaque « triviale », simple à mettre en œuvre, qui reste cependant très efficace et très utilisée par les attaquants.
Implémenter des mécanismes de Rate Limiting pour contrer les attaques DoS et les attaques brute force
Sécuriser des APIs contre des attaques DoS ou des attaques brute force passe par l’implémentation de mécanismes de Rate Limiting. Ils permettent de protéger les APIs et les autres services contre une utilisation excessive et abusive, afin d’assurer leur disponibilité.
Le principe du Rate Limiting est très simple. Il s’agit d’anticiper le fait qu’un ou plusieurs client(s) – système – peuvent utiliser plus que leur « juste » part d’une ressource, via l’envoi de requêtes. Et en limitant le nombre de requêtes qu’un utilisateur donné est autorisé à envoyer dans un laps de temps défini, on peut réduire le risque d’attaque DoS ou d’attaque brute force.
En effet, par exemple suite à l’authentification d’un utilisateur, votre API ou votre application peut appliquer des seuils ou des quotas qui permettent de restreindre ce qu’il est autorisé à faire, et notamment la limite des requêtes qu’il peut envoyer. Vous pouvez, par exemple, limiter chaque utilisateur à un certain nombre de requêtes d’API par heure, afin de l’empêcher d’inonder le système de trop de demandes.
De même, avant authentification d’un utilisateur, vous pouvez appliquer des seuils pour restreindre le nombre de requêtes dans l’ensemble, ou à partir d’une adresse IP ou d’une plage particulière. Ainsi, si un Rate Limiting est implémenté, votre API gardera la trace du nombre de requêtes et rejettera celles au-dessus du seuil autorisé. Par ailleurs, vous pouvez appliquer des règles commandant de fermer complètement les connexions lorsque la limite fixée est dépassée ou de ralentir le traitement des requêtes. Ce processus est connu sous le nom d’étranglement « Throttling ».
En somme, le Rate Limiting permet de prévenir l’épuisement des ressources via une gestion des règles et quotas. Il existe différentes techniques permettant d’appliquer du Rate Limiting, chacune ayant ses propres spécificités : Token bucket (seau à jetons), Leaky bucket (seau percé), Fenêtre fixe et Fenêtre glissante.
Pour conclure cette partie, un conseil de pentesters : ne réinventez pas la roue ! Des vulnérabilités apparaissent souvent en raison de développements personnalisés de fonctionnalités ou de mécanismes critiques. Il existe de nombreux frameworks connus, reconnus et solides pour implémenter des mécanismes de Rate Limiting efficaces et sécurisés. Vous devriez donc privilégier ces solutions pour éviter d’ouvrir d’autres brèches.
Défaut de validation des entrées utilisateurs et attaques par injection
Injections de code
L’injection de code est l’un des types d’attaques par injection les plus courants. Si les attaquants connaissent le langage de programmation utilisé par une application ou une API, ils peuvent injecter du code via des champs de saisie de texte pour forcer le serveur web à exécuter les instructions souhaitées.
Injections SQL
Les injections représentent une part importante des vulnérabilités rencontrées dans les applications et les APIs. La plus connue et la plus redoutable : l’injection SQL.
Dans une attaque par injection SQL, un attaquant injecte des données pour manipuler des commandes SQL, et ainsi interagir avec la base de données par le biais de requêtes non prévues. Ces failles peuvent conduire à des vols, suppressions ou manipulations des données stockées. Pire encore : si les droits sont trop permissifs, cela peut même aboutir à une compromission du serveur.
Voyons cela plus en détail avec un exemple concret :
On peut imaginer un endpoint d’API qui renvoie les informations d’un pays en fonction de son « Country_Code ».
URL : http://localhost:8042/?CC=FR
[
{
"nom": "France",
"code": "FR"
}
]
Pour effectuer l’action escomptée, notre requête interagit avec une base de données. Ci-dessous, la requête SQL que doit lancer le serveur sur la base de données.
SELECT nom_fr as nom , alpha2 as code FROM Pays WHERE alpha2= "FR"Une implémentation vulnérable de cette action consiste à concaténer directement la valeur du paramètre « CC » dans la requête SQL.
Exemple de code PHP vulnérable :
<?php
try{
$db = new PDO('sqlite:database/base.sqlite3');
$db->setAttribute(PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_ASSOC);
$db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); // ERRMODE_WARNING | ERRMODE_EXCEPTION | ERRMODE_SILENT
} catch(Exception $e) {
echo "Impossible d'accéder à la base de données SQLite : ".$e->getMessage();
die();
}
$recipesStatement = $db->prepare('SELECT nom_fr as nom ,alpha2 as code FROM pays where alpha2 = "'.$_GET['CC'].'"');
$recipesStatement->execute();
$recipes = $recipesStatement->fetchAll();
header('Content-Type: application/json; charset=utf-8');
echo json_encode($recipes, JSON_PRETTY_PRINT);
Comme nous pouvons le voir, le paramètre CC qui est contrôlé par l’utilisateur est directement concaténé à la requête.
Maintenant, supposons que sur cette même base de données, il existe une table ‘users’ qui contient les adresses email et les mots de passe des utilisateurs inscrits sur l’application. Intéressons-nous à ce qu’il se produit si un attaquant effectue la requête suivante :
URL : http://localhost:8042/?CC=FR%22+UNION+SELECT+email,password+FROM+user-- 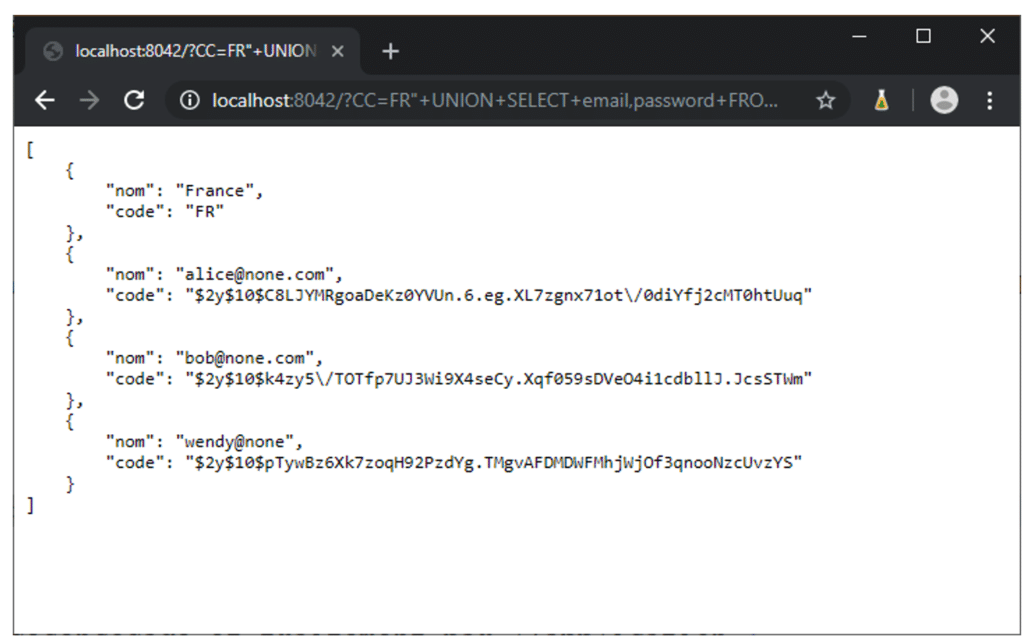
En plus du nom du pays, cette requête permet de récupérer l’ensemble des utilisateurs ainsi que le hash de leur mot de passe.
C’est une exploitation d’injection SQL. Une vulnérabilité qui permet à un attaquant de « pervertir » la requête SQL générée par l’application. Avec ce comportement, il est possible pour l’attaquant de lire voire d’altérer les données présentes dans la base de données. Ce qui est bien évidemment une vulnérabilité critique qui serait remontée dans un rapport, s’il agissait d’un pentest d’une API ou d’une application.
Valider les entrées utilisateurs pour déjouer les attaques par injection
Valider les entrées utilisateurs est la meilleure défense contre les injections SQL et les injections de code. En théorie, il faut partir du principe que les données reçues par une application ou une API ne peuvent pas être considérées comme « toujours » sûres. En pratique, il s’agit de mettre en œuvre des mécanismes permettant de vérifier que les entrées utilisateurs correspondent aux paramètres attendus pour éviter ce type de vulnérabilités.
La méthode la plus efficace pour se protéger contre les injections SQL reste l’utilisation de requêtes préparées (prepared statements), qui permettent de dissocier les commandes SQL des données envoyées par un utilisateur.
Pour illustrer cette méthode, revenons sur notre exemple mentionné plus haut, avec cette fois-ci la recommandation de correction.
La correction consiste à utiliser des requêtes préparées. Sur la documentation PHP, nous pouvons voir les informations suivantes :
- La requête ne doit être analysée (ou préparée) qu’une seule fois, mais peut être exécutée plusieurs fois avec des paramètres identiques ou différents. Lorsque la requête est préparée, la base de données va analyser, compiler et optimiser son plan pour exécuter la requête. Pour les requêtes complexes, ce processus peut prendre assez de temps, ce qui peut ralentir vos applications si vous devez répéter la même requête plusieurs fois avec différents paramètres. En utilisant les requêtes préparées, vous évitez ainsi de répéter le cycle analyse/compilation/optimisation. Pour résumer, les requêtes préparées utilisent moins de ressources et s’exécutent plus rapidement.
- Les paramètres pour préparer les requêtes n’ont pas besoin d’être entre guillemets ; le pilote gère cela pour vous. Si votre application utilise exclusivement les requêtes préparées, vous pouvez être sûr qu’aucune injection SQL n’est possible (Cependant, si vous construisez d’autres parties de la requête en vous basant sur des entrées utilisateurs, vous continuez à prendre un risque).
Ainsi le code suivant est correctement protégé contre les injections SQL :
<?php
try{
$db = new PDO('sqlite:database/base.sqlite3');
$db->setAttribute(PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_ASSOC);
$db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); // ERRMODE_WARNING | ERRMODE_EXCEPTION | ERRMODE_SILENT
} catch(Exception $e) {
echo "Impossible d'accéder à la base de données SQLite : ".$e->getMessage();
die();
}
$recipesStatement = $db->prepare('SELECT nom_fr as nom ,alpha2 as code FROM pays where alpha2 = :CC');
$recipesStatement->execute([
'CC' => $_GET['CC']
]);
$recipesStatement->execute();
$recipes = $recipesStatement->fetchAll();
header('Content-Type: application/json; charset=utf-8');
echo json_encode($recipes, JSON_PRETTY_PRINT);
Comme nous pouvons le voir, la différence avec le code vulnérable est que les paramètres venant d’un utilisateur ne sont plus concaténés avec la requête, mais directement fournis à l’exécution de la requête. Ceci montre aussi qu’une requête préparée peut quand même être vulnérable à l’injection SQL si les données sont concaténées. Car dans l’exemple vulnérable c’était déjà une requête préparée qui était utilisée.
Défaut de chiffrement des données et attaques Man In The Middle
Attaques Man In The Middle
Une attaque Man In the Middle est un type d’attaque dans lequel une personne malveillante s’insère dans une communication ou un transfert de données entre un client et un serveur, un serveur et un serveur ou un client et un client. Son objectif peut être multiple : il peut s’agir tout simplement d’intercepter des données sensibles (mots de passe, informations bancaires, données personnelles, documents sensibles, etc.) ou manipuler la communication afin d’y introduire un malware par exemple.
Ce type d’attaque est possible si et seulement si les communications ne sont pas chiffrées. Il est donc assez facile de s’en prémunir.
Chiffrer les données avec TLS pour contrer les attaques Man In The Middle
Le chiffrement est l’un des aspects les plus élémentaires pour assurer la sécurité d’une API ou d’une application. En effet, TLS (successeur de SSL) est un protocole de chiffrement qui assure la sécurité des communications sur un réseau informatique. Lorsqu’elles sont sécurisées par TLS, les connexions entre un client et un serveur présentent une ou plusieurs des propriétés suivantes :
- La connexion est privée (donc sécurisée) parce les données transmises sont chiffrées.
- Les clés de chiffrement sont générées de manière unique pour chaque connexion et sont basées sur un secret partagé négocié au début de la session.
- La connexion garantit l’intégrité car chaque message transmis comprend une vérification de l’intégrité du message à l’aide d’une signature ce qui permet d’éviter toute perte ou altération non détectée des données pendant la transmission.
L’utilisation de ce protocole de chiffrement permet donc de réduire voire d’annuler les risques d’attaques de type Man In The Middle. Par ailleurs, pour renforcer la sécurité, nous recommandons d’implémenter l’en-tête HSTS (http Strict Transport Security) sur vos serveurs afin de forcer un navigateur à utiliser des connexions sécurisées HTTPS. Sans ce paramétrage, vous courez le risque que des utilisateurs accèdent à votre domaine sans le protocole HTTPS, ce qui peut ouvrir une brèche dans les communications.
Sécurité de l’authentification et des autorisations dans les APIs : jetons JWT, OAuth 2.0 et OpenID
Implémentation de Tokens JWT
Les jetons JWT (JSON Web Token) sont générés par un serveur lors de l’authentification d’un utilisateur, avant transmission au client. Ils seront renvoyés via chaque requête HTTP, ce qui permet au serveur d’identifier l’utilisateur. Pour ce faire, les informations contenues dans le jeton sont signées à l’aide d’une clé privée présente sur le serveur. Quand il recevra à nouveau le jeton, le serveur n’aura qu’à comparer la signature envoyée par le client et celle qu’il aura générée avec sa propre clé privée et à comparer les résultats. Si les signatures sont identiques, le jeton est valide.
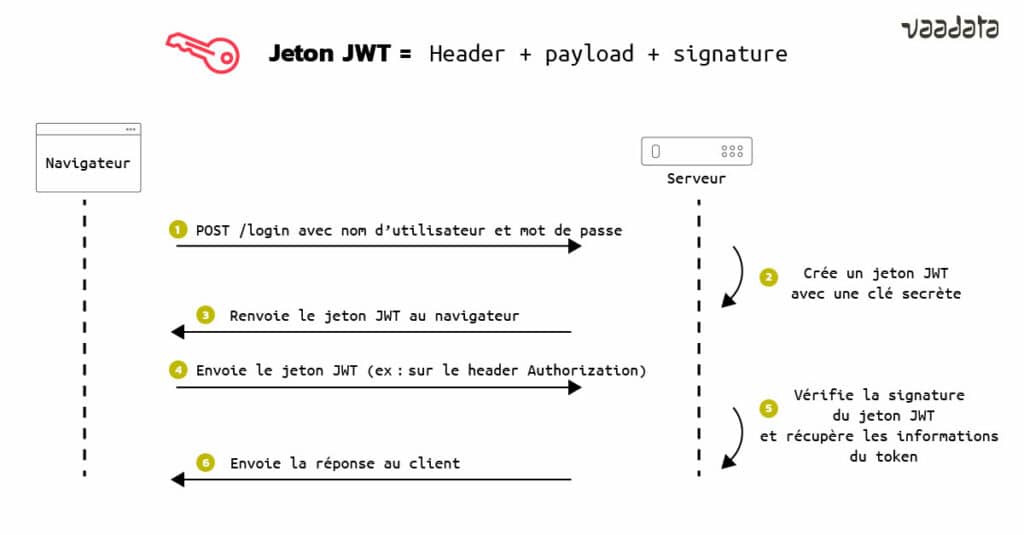
Un token JWT est donc utilisé pour authentifier les utilisateurs et ainsi leur attribuer des droits. Une mauvaise implémentation peut donc être source de vulnérabilités. En effet, un utilisateur pourrait par exemple augmenter ses droits sur une plateforme (élever ses privilèges et devenir admin par exemple) ou accéder aux données d’un autre utilisateur.
Une vulnérabilité courante : une mauvaise configuration côté serveur des tokens. Pour illustrer cette vulnérabilité, un petit aparté sur les composantes d’un Token JWT. Dans la plupart des cas, un token JWT contient généralement :
- Une tête « Header », l’algorithme utilisé pour la signature, en JSON encodé en Base64 (généralement HS256)
- Un corps « Payload », les informations du jeton. Il peut s’agir du nom d’utilisateur, du rôle de l’utilisateur ou encore de son email.
- Un cœur « LA signature », qui correspond à la concaténation des parties « Header » et « Payload » chiffrée avec la clé privée (détenue par le serveur).
Le standard JWT permet la non-utilisation d’un algorithme pour signer le token. Cela est bien entendu une très mauvaise pratique, car dans le cas mentionné auparavant, un utilisateur pourrait modifier ses droits à la volée (passer du “role“ : “user“ à “role“ : “user2“ ou “role“ : “admin“), sans qu’aucun contrôle ne soit effectué par le serveur. De la même manière, si la configuration effectuée au niveau du serveur accepte différents algorithmes et la variable “none“, qui consiste à ne pas avoir de fonctions cryptographiques, il sera possible pour un attaquant de contourner la fonction de vérification d’intégrité pour accéder aux donnés d’autres utilisateurs voire de l’admin.
Rien de plus simple donc pour se prémunir contre ce type de risques : choisir un algorithme fiable (du HMAC SHA256) et configurer le serveur de manière à toujours contrôler, donc refuser la variable “none“.
Par ailleurs, les attaquants peuvent essayer de deviner la clé privée détenue par le serveur, via du brute force. Un conseil donc ! Éviter de définir une chaine de caractères trop évidente car un mauvais mot de passe peut être craqué sans trop d’efforts, avec les outils adéquats et très peu de compétences en hacking.
Un autre cas rencontré couramment : l’exposition, par certaines fonctionnalités d’une API, des jetons d’autorisation JWT (Bearer Token) dans les URLs. Cette configuration expose les tokens (et donc la sécurité des comptes liés) à des risques ; les navigateurs, serveurs et autres éléments intermédiaires n’assurant pas forcément la sécurité des URLs.
La recommandation de correction est, ici, de faire en sorte que la fonctionnalité de l’API transmette les tokens Bearer via les headers HTTP. Il s’agit par ailleurs d’une recommandation de l’utilisation des Bearer dans OAuth2 (sur lequel nous reviendrons en détails dans un prochain article). Et s’il est difficile ou impossible techniquement de déplacer les tokens dans les headers, quelques mesures peuvent tout de même permettre de réduire le risque de compromission. Il faut notamment s’assurer que :
- Les clients effectuant les requêtes incluent le header « Cache-Control: no-store »
- Le serveur retourne également un header « Cache-Control: no-store » dans ses réponses
- La durée de vie du token est faible.
Pour plus d’informations sur les tokens JWT, vous pouvez consulter notre article dédié sur ce sujet : Jetons JWT et sécurité – principes et cas d’utilisation.
OAuth 2.0 & OpenID
OAuth 2.0 & OpenID sont des standards ô combien essentiels permettant de sécuriser l’authentification et les autorisations dans les APIs. OAuth 2.0 permet d’autoriser une application de tout type à utiliser une API tierce pour le compte d’un utilisateur. OpenID, quant à lui, est un protocole permettant de vérifier l’identité d’un utilisateur auprès d’un serveur d’autorisation pour obtenir des informations sur celui-ci.
Ces 2 protocoles sont considérés aujourd’hui comme des éléments essentiels de la sécurité des APIs. C’est pourquoi, nous y consacrerons un article dédié, qui reviendra sur les principes, les cas d’utilisation ainsi que la configuration d’OAuth 2.0 & OpenID.
Inscrivez-vous à notre Security Digest (un email par mois sur des contenus orientés sécurité) pour le recevoir dès publication :
Problèmes de droits et attaques sur les processus logiques des APIs : Mass Assignment, Manque de contrôle d’accès et IDOR
Dans le cas d’une API REST par exemple, la norme est de manipuler une entité par des méthodes prédéfinies. Par exemple, imaginons une plateforme permettant la gestion de fichiers, avec une entité file qui contient les attributs suivants :
- Id
- Name
Il est donc possible de déduire facilement les potentiels appels REST suivant :
| Méthode | Chemin | Description |
| GET | /file | Récupère tous les fichiers de la plateforme |
| GET | /file/<id> | Récupère le fichier avec l’id |
| POST | /file | Créé un fichier |
| PUT/PATCH | /file/id | Remplace/Modifie le fichier avec l’id |
| DELETE | /file/id | Supprime le fichier |
Ceci est bien évidemment une supposition de fonctionnement des méthodes. La récupération des fichiers (GET /file) peut par exemple s’appuyer sur l’identifiant de l’utilisateur et retourner uniquement ses fichiers.
Il est donc facile pour un attaquant d’adapter des requêtes REST pour essayer de manipuler les ressources. Il est donc important de s’assurer que chaque accès vérifie correctement les droits de l’utilisateur et réagit en conséquence.
Mass Assignment
Dans certains cas l’application accepte que l’utilisateur puisse modifier une ressource, mais uniquement un ensemble restreint d’attributs. Par exemple une application permet à un utilisateur de modifier son profil. Nous allons envoyer à la plateforme un JSON de cette forme :
#POST request body
{
"nom":"Billy",
"prenom":"Doe"
}
La réponse de la plateforme est la suivante :
#Réponse body
{
"nom":"Billy",
"prenom":"Doe",
"role":"User"
}
Si l’API n’est pas bien configurée, il peut être possible pour Billy d’envoyer la requête suivante :
#POST request body
{
"nom":"Billy",
"prenom":"Doe",
"role":"super_super_Admin"
}
Et l’application lui retournera :
#Réponse body
{
"nom":"Billy",
"prenom":"Doe",
"Role":"super_super_Admin"
}
Ceci montre que l’application autorise n’importe qui à modifier son rôle, et donc permet une élévation de privilège.
Manque de contrôle d’accès et IDOR
Les références directes d’objet non sécurisées (insecure direct object references en anglais, abrégé IDOR) sont des failles courantes qui permettent aux attaquants de contourner les autorisations et d’accéder directement aux ressources en modifiant la valeur d’un paramètre utilisé pour pointer directement vers un objet. Ces ressources peuvent être des entrées de base de données appartenant à d’autres utilisateurs, des fichiers dans le système, etc.
Il est courant sur une API d’avoir accès à une ressource par l’intermédiaire d’id. Si les droits ne sont pas correctement vérifiés par l’application un attaquant peut facilement modifier la requête pour accéder à des objets ne lui appartenant pas. Par exemple Billy voit que la requête selon lui permet de récupérer son fichier :
#GET https://un-site-ultra-random.com/file/42 Et l’API lui retourne la réponse suivante :
#Réponse body
{
"id":42,
"url": "//ressource_image_chat_78b369a7-960e-4e02-bdc7-4546c741ea65.jpg"
}
Il se décide donc à rejouer la requête suivante et voir le résultat :
#GET https://un-site-ultra-random.com/file/41 Résultat :
#Réponse body
{
"id":41,
"url": "//ressource_entreprise_tres_importante_49f18c2b-1f5c-452a-b222-9d1eea743123.jpg"
}
Il arrive donc à récupérer une URL ne lui appartenant pas et donc potentiellement avoir accès à des fichiers ne lui appartenant pas. Ceci est dû au fait que l’application prend les entrées fournies par l’utilisateur et les utilise pour récupérer un objet sans effectuer suffisamment de contrôles des droits.
Il est donc nécessaire de s’assurer pour chaque requête que l’utilisateur possède correctement les droits pour la manipuler.
Par ailleurs, dans certains cas, les applications utilisent des UUIDs (par exemple : 736fb654-a3ac-446c-8cdf-3afd85c47e06) et s’appuient sur une protection par obscurité. La protection par obscurité peut être un plus, mais il est quand même recommandé de s’assurer que l’utilisateur possède bien les droits appropriés même avec des id qui ne peuvent pas être devinés. En effet il arrive que des fuites de données permettent de découvrir des uuid.
Vérifier les droits utilisateurs pour prévenir l’élévation de privilèges
Les problèmes de droits, généralement synonymes de manque de contrôle d’accès, sont sûrement les vulnérabilités les plus répandues dans les APIs, avec comme « tête de proue » : les IDOR (principale vulnérabilité découverte lors de tests d’intrusion).
Pour s’en prémunir : les droits d’un utilisateur qui effectue une requête doivent systématiquement être vérifiés par le serveur. La requête doit être acceptée uniquement si l’utilisateur possède effectivement les droits appropriés. De manière globale, le serveur web doit toujours vérifier les droits de l’utilisateur quant à l’utilisation d’une fonctionnalité et des paramètres saisis.
Failles inhérentes aux APIs GraphQL
Les APIs GraphQL partagent certaines vulnérabilités courantes des APIs REST mentionnées dans le cœur de cet article. Cependant leur architecture étant différente, elles font face à des risques spécifiques : introspection, problèmes de droits, etc.
Nous reviendrons sur les vulnérabilités inhérentes aux APIs GraphQL dans un article dédié, avec, comme toujours, des cas concrets ainsi que des bonnes pratiques pour se prémunir contre les attaques.
Réaliser un pentest d’API pour évaluer les risques et renforcer la sécurité
Les APIs sont des cibles particulièrement intéressantes pour les attaquants, en raison de leur exposition, de leur caractère central dans le SI – vu les données sensibles qui y transitent – et de nombreuses vulnérabilités. La sécurité de vos APIs est donc essentielle. Cela passe par l’implémentation de bonnes pratiques en termes de développement, de configuration, d’intégration, et surtout d’audits de sécurité offensifs (de tests d’intrusion donc) pour évaluer la résistance de vos APIs face à des attaques réelles.
En effet, un test d’intrusion consiste à tester tout type de système avec un objectif double : identifier les vulnérabilités qu’un attaquant pourrait exploiter et proposer des correctifs de sécurité. Lors d’un pentest d’API, il s’agit notamment de rechercher des vulnérabilités à la fois côté serveur et sur la couche applicative.
Exemples de failles côté serveur :
- Services ouverts et mal sécurisés
- Logiciels non mis à jour
- Éléments de sécurité contournables
- Erreurs de configuration
Exemples de failles sur les APIs (OWASP Top 10 API) :
- Défaut de contrôle d’accès au niveau des fichiers
- Vulnérabilités dans la gestion de l’authentification
- Exposition de données sensibles
- Manque de Rate Limiting
- Défaut de contrôle d’accès au niveau des rôles utilisateurs
- Mass Assignment
- Problèmes de configuration
- Failles d’injections
- Défaut de gestion des actifs
- Manque de logging et de monitoring
Par ailleurs, un pentest, à la différence des outils automatisés (scanners de vulnérabilités), intègre une phase manuelle d’exploitation des failles ; ces dernières servant généralement de « pivot » pour découvrir d’autres vulnérabilités.
Quel que soit le périmètre des tests, un rapport complet est réalisé suite à tout pentest. Il inclut la méthodologie suivie, les vulnérabilités identifiées, le niveau de criticité, l’exploitation possible ainsi que des recommandations de correction. Le pentest pourra être complété par une phase de validation des corrections permettant de vérifier leur bonne implémentation et l’absence d’effets de bord.