
Introduction
Avec des menaces informatiques en constante évolution, les entreprises doivent veiller à protéger leur SI contre les vulnérabilités potentielles. Les scanners de vulnérabilités se sont imposés comme des outils essentiels pour identifier ces failles avant qu’elles ne soient exploitées lors d’attaques.
Parmi les nombreux scanners disponibles sur le marché, Nuclei se démarque grâce à sa flexibilité, ses performances et son approche open source.
Dans cet article, nous examinerons en détail pourquoi Nuclei est un outil essentiel pour détecter les vulnérabilités. Nous aborderons également ses principales fonctionnalités et des exemples concrets d’utilisation.
Guide complet sur Nuclei
Présentation de Nuclei
Qu’est-ce que Nuclei ?
Nuclei est un scanner de vulnérabilités open source, développé par la société ProjectDiscovery.
Conçu pour être à la fois flexible et performant, Nuclei permet d’automatiser la détection de vulnérabilités dans les systèmes informatiques (apps web, infras cloud, réseaux, etc.).
Avant de continuer, il est essentiel de souligner que l’utilisation de Nuclei peut générer un trafic important et qu’il est illégal de l’utiliser sans l’autorisation préalable du propriétaire du système testé.
Nuclei, un outil open source qui repose sur des templates
Nuclei s’appuie sur des modèles de détection (templates) personnalisables, au format YAML. Ces templates, comme nous le verrons plus loin, permettent de définir et classer une vulnérabilité suivant sa criticité, son type, sa catégorie et un ensemble d’autres paramètres.
De plus, Nuclei se distingue par sa communauté active et la richesse de ses contributions open source, qui permettent une mise à jour régulière des templates et l’ajout continu de nouveaux. Aujourd’hui on dénombre plus de 8000 templates disponibles.
Par ailleurs, le moteur de Nuclei utilise aussi du template clustering. En d’autres termes, il est conçu pour optimiser le nombre de requêtes qu’il envoie, afin d’accélérer le scanner et réduire le trafic réseau.
À titre d’exemple, imaginons que 5 modèles de templates différents doivent chacun effectuer une requête GET vers une page de connexion ; le moteur n’en effectuera qu’une seule, et le résultat sera ensuite traité séparément en fonction de chacune des différentes règles des templates.
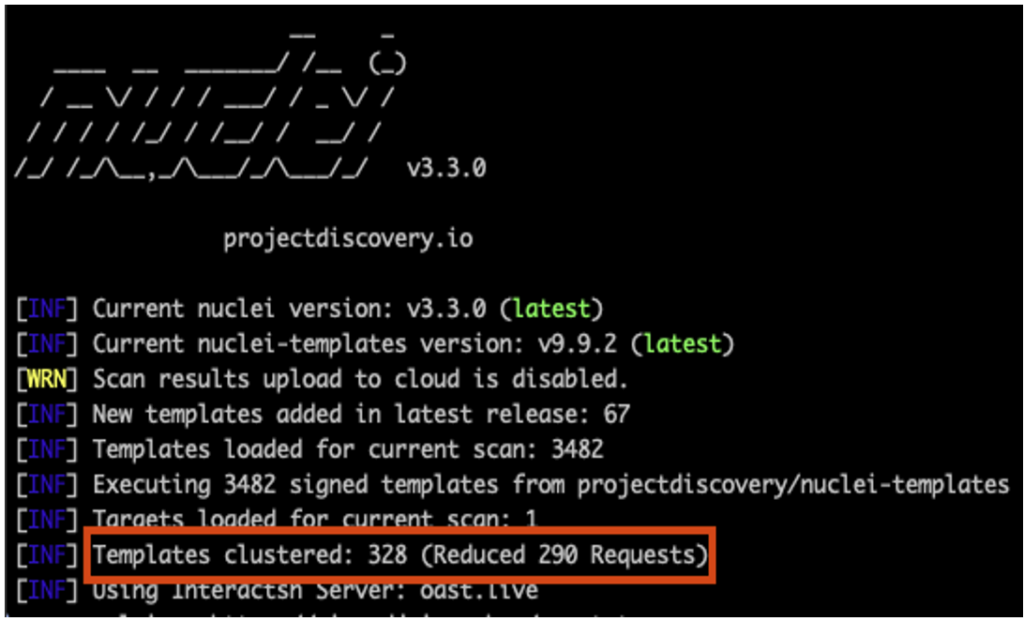
Ainsi, grâce à sa capacité à exécuter des milliers de tests, Nuclei s’impose comme un outil indispensable pour découvrir des vulnérabilités afin de les corriger avant qu’elles ne soient exploitées lors d’attaques.
Son architecture modulaire, adaptable à divers besoins, en fait le scanner de vulnérabilités de référence qu’il s’agisse de tests de sécurité basiques ou d’analyses plus approfondies et spécifiques.
Principes et fonctionnement de Nuclei
Dans la suite de cet article, nous verrons que Nuclei est facile à prendre en main. Toutefois, nous découvrirons progressivement qu’il révèle tout son potentiel quand on prend le temps de le configurer ou de créer ses propres templates.
Utilisation basique de Nuclei
Dans son utilisation la plus basique, Nuclei attend simplement une URL avec le paramètre -u, ou, pour un fichier contenant plusieurs URL, le paramètre -l :
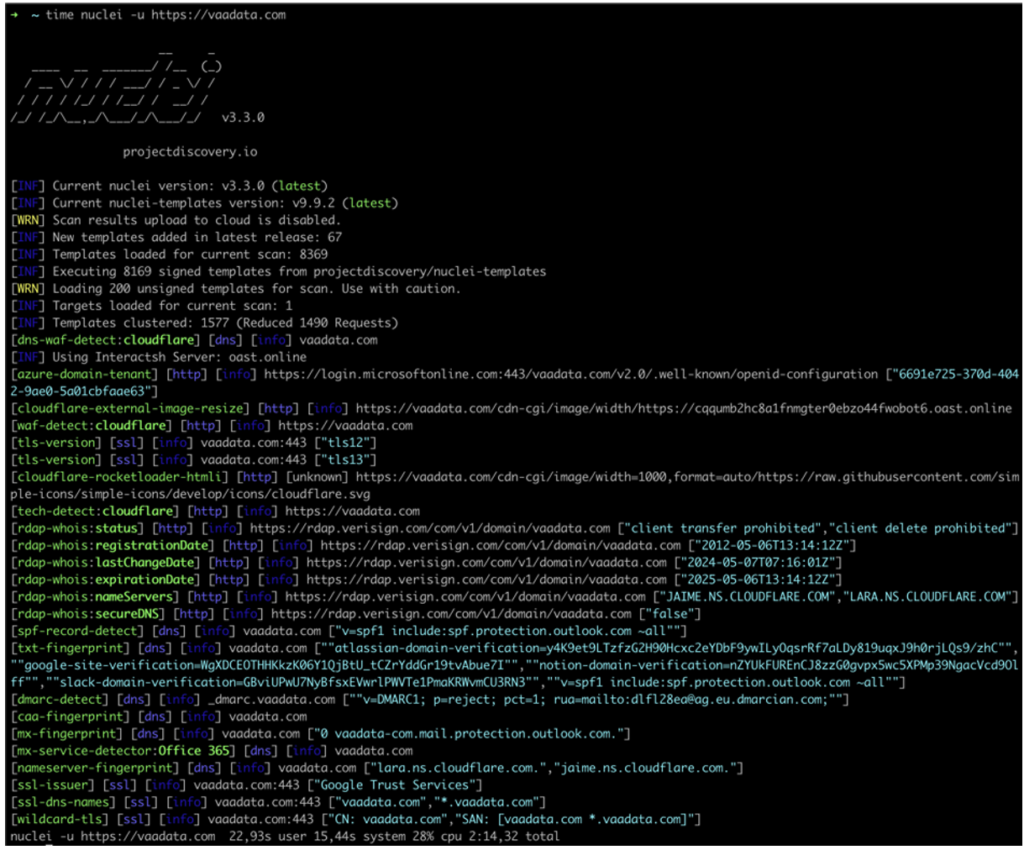
Ce scan permet de recueillir de nombreuses informations.
Comme aucune option spécifique n’a été précisée, Nuclei a simplement exécuté tous les templates disponibles dans sa configuration par défaut (ce qui ne correspond pas à l’intégralité des templates disponibles !).
La durée du scan a été d’environ 2 minutes avec 8169 templates Nuclei utilisés sur une seule cible. Notons cependant que le temps de réponse du serveur peut varier.
Néanmoins, avec cette configuration, on sacrifie complètement la notion de rapidité évoquée précédemment. En effet, les templates utilisés par Nuclei couvrent un large éventail de vulnérabilités, et la plupart ne sont pas pertinents pour notre cible, les rendant ainsi inutiles.
Utilisation avancée de Nuclei
Après avoir exploré l’utilisation de Nuclei dans sa forme la plus basique, nous allons maintenant découvrir les nombreuses options de configuration qui s’offrent à nous.
Filtrage des templates
Le filtrage des templates est au coeur de l’utilisation de Nuclei. Il est donc essentiel de savoir comment l’utiliser correctement. Cela vous permettra de sélectionner efficacement les templates les plus adaptés.
Nuclei repose sur un système de tags. Lors de la création d’un template, un ou plusieurs tags peuvent être ajoutés dans le fichier YAML. Ces derniers permettent de classifier les templates selon différents critères.
Et pour les indiquer, il suffit d’utiliser le flag -tag lors de l’exécution de Nuclei, afin de filtrer les templates.
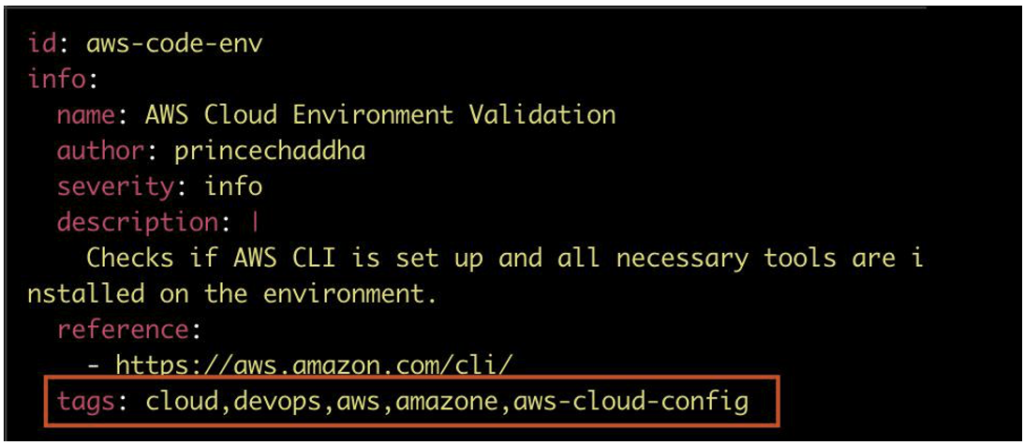
Ainsi, en précisant ce flag avec, par exemple le tag cloud, 42 templates sont chargés.
Et pour retrouver l’ensemble des tags disponibles, on peut utiliser le flag -tgl.
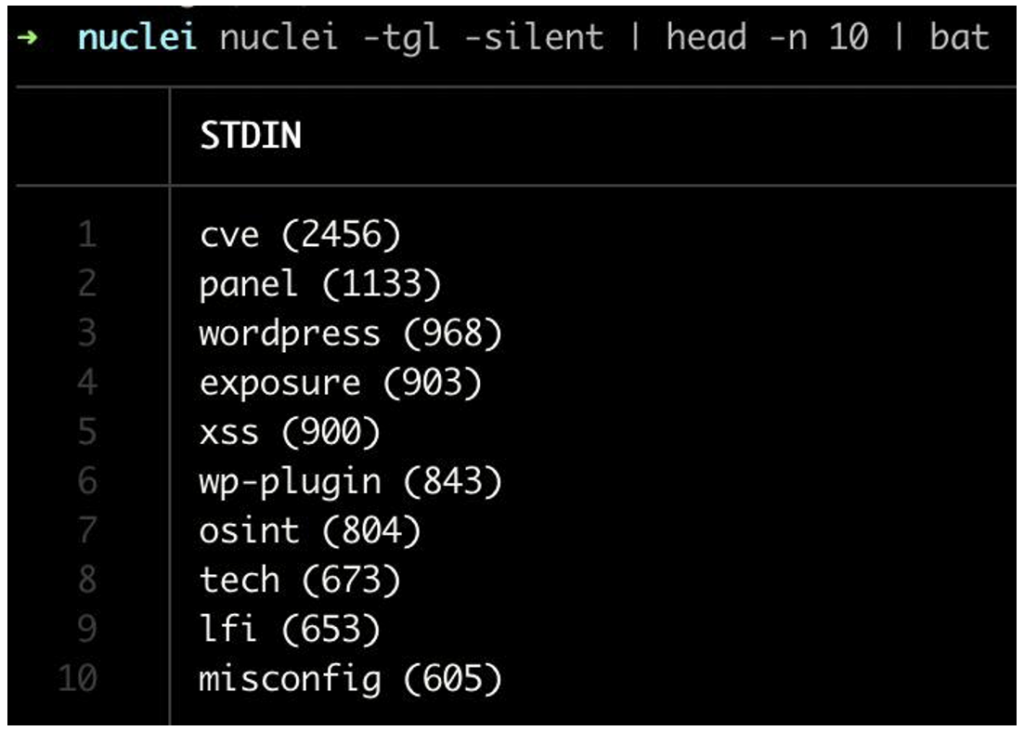
On retrouve sans surprise le tag cve en première position, avec actuellement 2456 templates associés.
Une autre option régulièrement utilisée est -t/-template, avec comme argument un chemin de fichier/dossier, pour charger les templates correspondants.
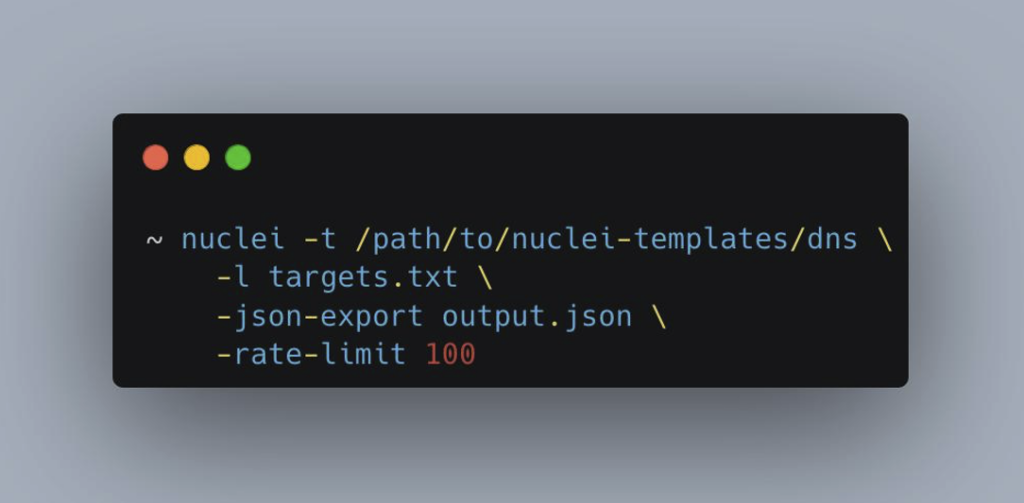
Choisir les templates les plus adaptés n’est pas toujours une tâche simple. La meilleure approche reste de les sélectionner manuellement en s’appuyant sur les informations disponibles sur les technologies utilisées par votre ou vos cibles, et en choisissant précisément les tags correspondants.
Cependant, il est également possible d’automatiser ce processus. Nuclei propose pour cela l’option -as ou -automatic-scan, qui utilise Wappalyzer pour détecter les technologies employées, puis associe automatiquement les tags correspondants.
Une autre approche consiste à d’abord utiliser le tag tech pour la reconnaissance ; puis à sélectionner les tags appropriés en fonction des résultats obtenus. Pour une identification exhaustive, on peut ajouter l’option -headless, afin d’identifier les technologies utilisées côté client.
Enfin, il est possible de filtrer les résultats en incluant ou excluant certaines sévérités grâce à l’option -severity. Cela peut être utile lors d’un scan sur plusieurs cibles pour ignorer les vulnérabilités mineures.
Configuration et optimisation des scans via Nuclei
De nombreuses options sont disponibles pour configurer et/ou optimiser les scans. Voici une liste de celles que nous considérons comme les plus pertinentes :
| Option | Description |
|---|---|
| -timeout int | Temps d’attente avant de timeout \Défaut 5\ |
| -retries int | Nombre de tentative en cas d’échec de la requête \Défaut 1\ |
| -iserver, -interactsh-server string | Spécifier un serveur auto-hebergé |
| -H, -header string[] | Ajout de headers spécifiques à la requête, sous forme header:valeur |
| -r, -resolvers | Liste de résolveurs |
| -rl, -rate-limit int | Nombre de requête max par secondes \Défaut 150\ |
| -mhe, -max-host-error int | Nombre max d’erreurs par host avant de le supprimer du scan \Défaut 30\ |
| -sa, -scan-all-ips | Scanner toutes les IP associées à l’enregistrement DNS |
Filtrer la sortie
Nuclei offre de nombreuses options pour filtrer les résultats. Ces filtres permettent non seulement d’affiner l’analyse, mais aussi de faciliter l’exploitation et le stockage des données obtenues.
Voici un tableau récapitulatif des options les plus intéressantes :
| Option | Description |
|---|---|
| -silent | Permet de montrer uniquement les vulnérabilités |
| -ts | Pour ajouter l’heure du scan sur les vulnérabilités |
| -jsonl | Sortie au format JSON |
| -json-export <file> | Sortie au format JSON, enregistré dans le fichier <file> |
| -me <dir> | Sortie au format MD, enregistré dans le dossier <dir> |
| -store-resp | Enregistre toutes les requêtes/réponses dans le dossier output |
Écrire ses propres templates
Bien que le dépôt de templates de Nuclei soit richement fourni grâce à une communauté très active, certaines CVE avec un proof of concept public peuvent parfois manquer.
Il est également possible d’avoir des besoins spécifiques que les templates existants ne couvrent pas. Dans ces cas, il est possible de créer ses propres templates et de les publier sur le dépôt GitHub officiel de Nuclei.
Voyons maintenant leur structure.
Comme évoqué en préambule, tous les templates Nuclei utilisent YAML. C’est un langage de sérialisation des données lisible par l’homme, généralement utilisé pour écrire des fichiers de configuration.
Il se décompose en 4 grandes parties :
- L’identifiant du template
- Les informations du template
- Les données à envoyer
- Le filtre sur la réponse
Nous allons nous appuyer sur le template correspondant à la CVE-2022-22965 \Spring4Shell). Pour rappel, cette CVE mène à une exécution de commande à distance (RCE) si toutes les conditions sont réunies.
Identifiant du template
L’identifiant est unique à chaque template et permet, comme son nom l’indique, l’identification. Cet identifiant est affiché lorsque les conditions du template sont remplies.
Selon la documentation de Nuclei, il ne doit pas contenir d’espaces pour faciliter le parsing.
Dans notre exemple, l’identifiant correspond au nom de la CVE associée :
id: CVE-2022-22965Informations du template
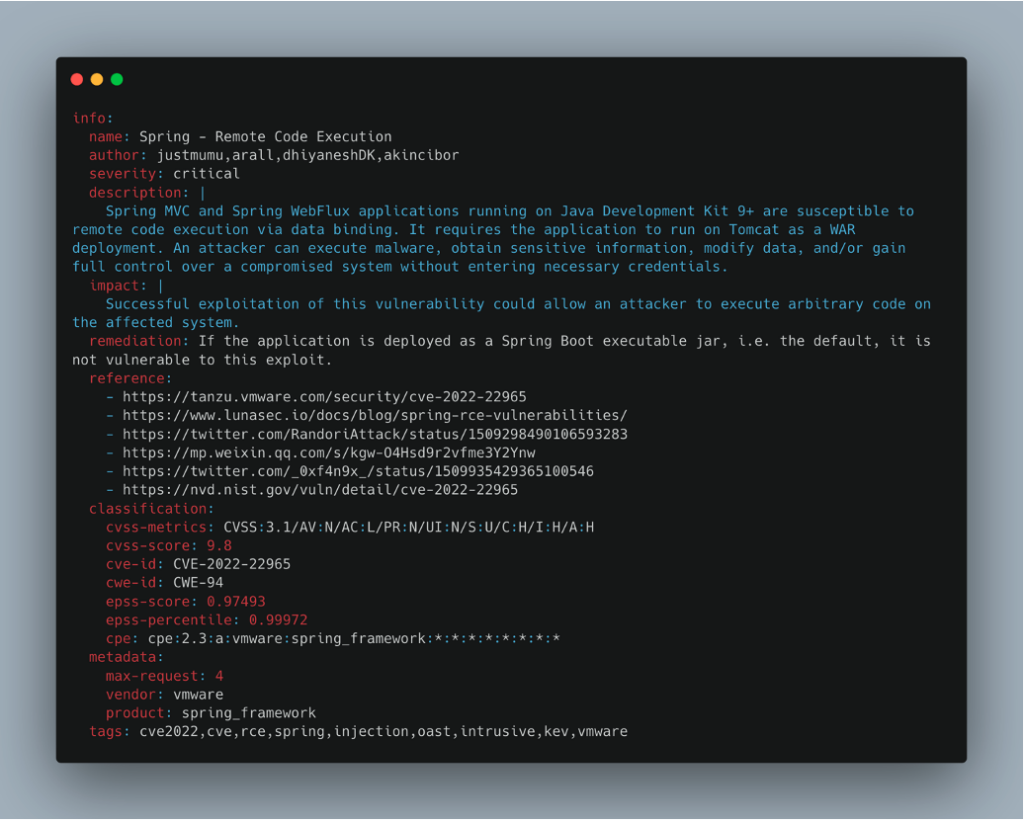
La deuxième section d’un template est le bloc info. Ce bloc contient diverses informations générales sur le template, telles que le nom de la vulnérabilité, l‘auteur, le niveau de criticité, une description, des références, et d’autres éléments qui fournissent un contexte à cette vulnérabilité.
Ce bloc inclut également les tags qui permettent d’identifier le template.
On y trouve fréquemment des métadonnées, comme une requête Shodan ou Fofa (des moteurs de recherche qui indexent les appareils connectés à Internet) pour identifier les cibles vulnérables. On peut aussi y spécifier le nom du fournisseur vulnérable ou le produit concerné.
Dans notre exemple, le template concerne une CVE et inclut donc une partie classification contenant diverses informations liées à cette CVE.
Protocole HTTP
Le troisième bloc se décompose en réalité en deux sous parties.
Le premier correspond à la requête qui sera envoyée à notre cible, et la manière dont elle doit être construite.
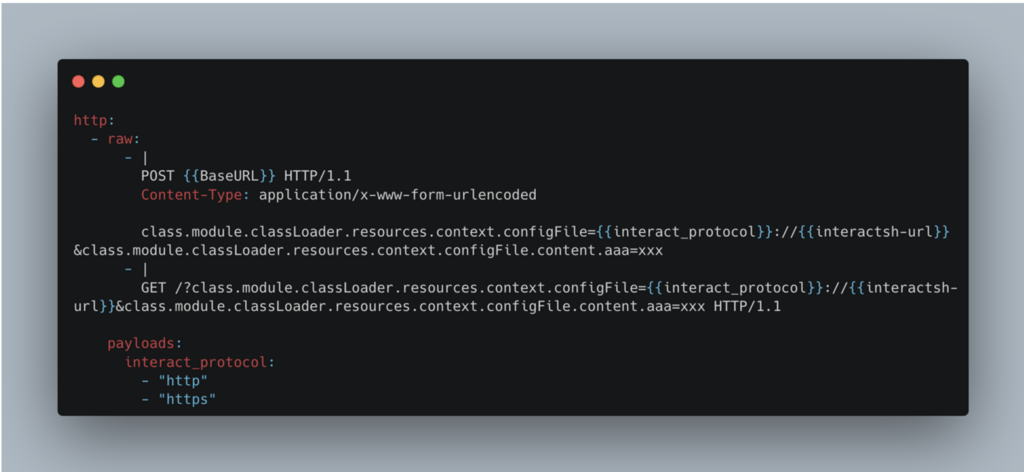
L’utilisation de raw offre une plus grande flexibilité dans la création du corps de la requête, en permettant l’intégration de fonctions DSL. Ces fonctions spécifiques sont conçues pour faciliter la création des templates. Voici quelques exemples :
| Fonction | Exemple | Description |
|---|---|---|
| contains(input, substring interface{}) bool | contains(body, “login succeeded”) | Vérifie si une chaîne contient une sous-chaîne |
| len(arg interface{}) int | len(body) | Renvoie la longueur de l’input |
| regex(pattern, input string) bool | regex(« file-([a-z0-9]+\ », body) | Teste l’expression régulière donnée par rapport à la chaîne d’input |
On peut également accéder à un ensemble de variables, soit définies manuellement, soit préétablies (‘builtins’). Par exemple, dans le cas ci-dessus, {{BaseURL}} représente l’URL complète (https://www.example.com/).
Ainsi, avec ce template, 2 requêtes seront effectuées :
- Une requête POST, avec une partie construite dynamiquement
\{{BaseURL}},{{interact_protocol}}et{{interactsh-url}}) - Une requête GET construite de la même manière.
Le deuxième correspond à l’interprétation de la réponse du serveur, et si elle répond au critère pour être vulnérable.
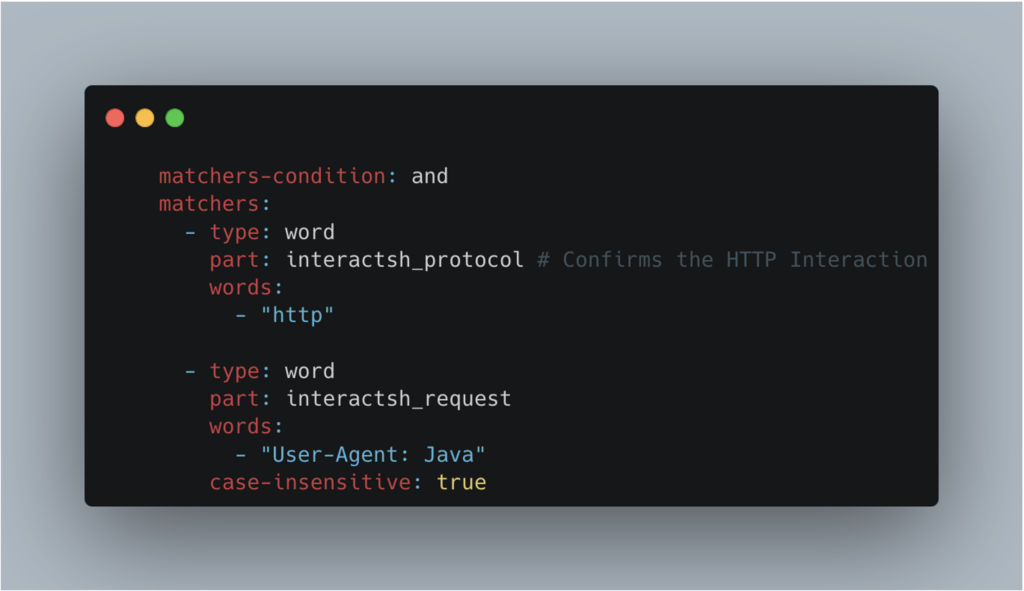
Nous avons ici deux matchers, présents pour vérifier une condition.
- Le premier va vérifier que le protocole utilisé pour l’interaction sur le serveur distant est
http - Le deuxième vérifie que le
User-Agent: Javaest présent dans les headers de la requête.
On remarque aussi matchers-condition : and, indiquant que les deux matchers doivent être validés pour que la cible soit considérée comme vulnérable.
Ainsi, pour résumer ce template, le but est de vérifier si la cible est vulnérable à la CVE-2022-22965 \Spring4Shell).
Deux requêtes sont effectuées pour chaque cible, une POST et une GET. Pour valider la vulnérabilité, il faut une interaction avec le serveur distant (celui fourni par Nuclei ou celui indiqué en utilisant le flag -iserver).
Le protocole utilisé doit être http, avec User-Agent: Java dans les headers.
Et si toute ces conditions sont réunies, le serveur est potentiellement vulnérable, et Nuclei remontera la vulnérabilité.
Nuclei met à disposition toute une palette d’outils pour réaliser des templates. Vous pouvez les retrouver sur la documentation officielle.
Cas d’utilisation de Nuclei lors d’audits
Maintenant que nous avons vu les bases de l’utilisation de Nuclei, parlons de ses avantages lors d’un audit. Et il présente plusieurs intérêts.
Nuclei est particulièrement puissant pour scanner un grand nombre de cibles, bien que ce ne soit pas toujours nécessaire lors de nos audits.
Tout d’abord, nous tenons notre liste de templates Nuclei à jour. Cet outil est efficace pour détecter les vulnérabilités des CVE avec un « proof of concept » existant. La base de données Nuclei, alimentée par une communauté active, en contient un grand nombre. Cela nous permet également d’identifier des vulnérabilités que nous pourrions autrement manquer.
La deuxième utilité de Nuclei est de nous fournir un « compte rendu » de nos cibles. Il collecte diverses informations qui orientent notre audit. Par exemple, quel type d’API est en place sur chaque cible ? Quels langages, frameworks et serveurs sont utilisés ? Y a-t-il des fichiers susceptibles de contenir des informations sensibles ? Ces données nous permettent de mieux comprendre notre cible et d’identifier d’éventuelles vulnérabilités dès le départ.
Nuclei peut également servir de point de départ pour des investigations plus approfondies. Les résultats obtenus orientent nos efforts manuels, nous permettant de cibler les zones les plus prometteuses ou les plus à risque.
De plus, la flexibilité de Nuclei, avec la possibilité d’intégrer des templates personnalisés, en fait un outil adaptable à des scénarios d’audit spécifiques. Nous pouvons l’ajuster selon les particularités de chaque mission, augmentant ainsi son efficacité et sa pertinence.
C’est donc un outil précieux à avoir dans notre arsenal. Son utilisation judicieuse peut considérablement améliorer l’efficacité et l’étendue de nos audits de sécurité.
Reconnaissance et découverte d’une surface d’attaque
Comme mentionné précédemment, Nuclei peut être très performant pour la phase de reconnaissance lors d’un audit de sécurité.
C’est l’une des premières étapes que nous effectuons. Il se peut que nous ne trouvions pas tout manuellement, et c’est là que Nuclei devient très utile.
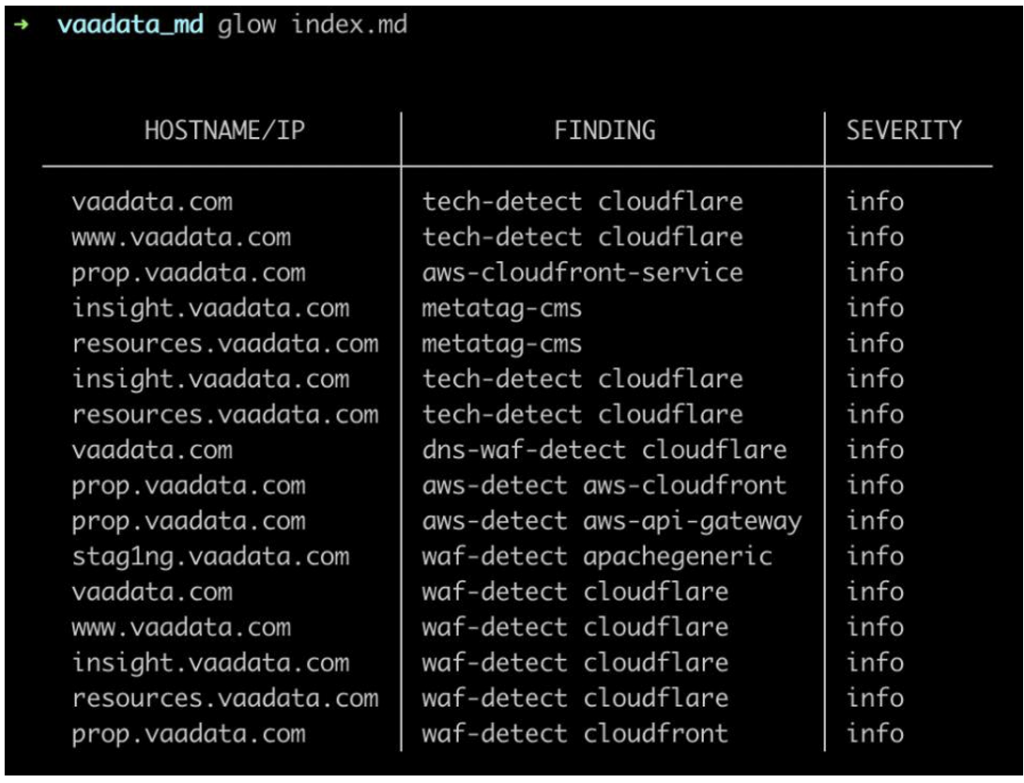
Prenons par exemple cette application web que nous avons déployée en local (OWASP Juice Shop) et sur laquelle nous avons lancé Nuclei avec cette commande basique :
Sans aucun paramètre spécifique, plus de 8000 templates ont été exécutés sur notre cible. Cette commande est utile à lancer en début d’audit pour mieux comprendre l’application.
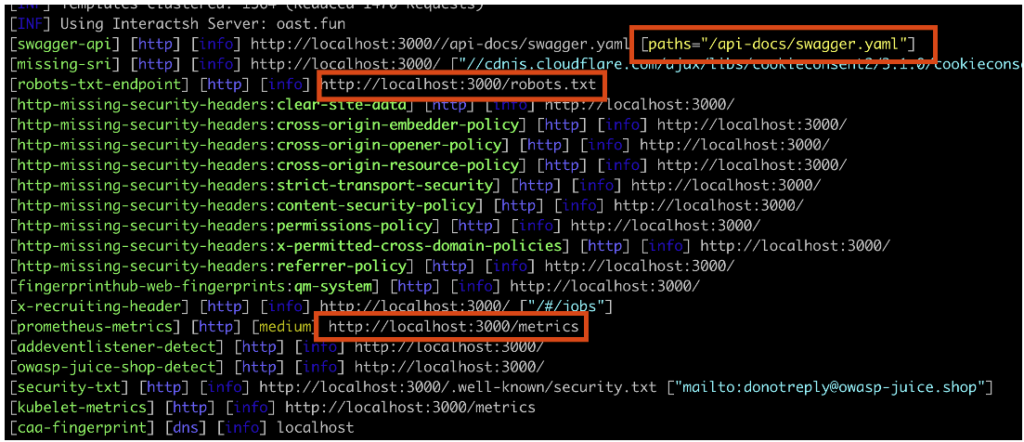
Ce scan a révélé plusieurs chemins intéressants.
D’abord, nous avons découvert une documentation d’API Swagger. Ce document décrit une API REST, les endpoints, les paramètres nécessaires, et la méthode à utiliser. Il peut être accessible publiquement intentionnellement ou par erreur de configuration. Grâce à ce document, nous avons identifié un endpoint accessible.
Le deuxième fichier découvert par le scan est le fichier robots.txt. Ce fichier est couramment utilisé par les applications web pour indiquer aux robots des moteurs de recherche les URL à explorer.
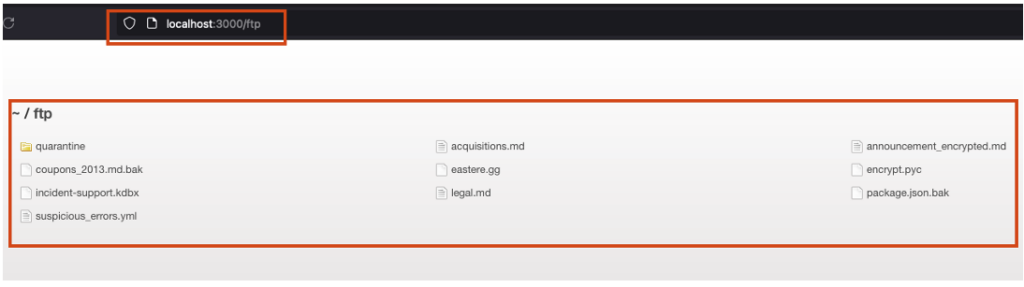
Parfois, des chemins confidentiels se trouvent dans ce fichier, comme ici. Le chemin /ftp y est indiqué, menant à des fichiers sensibles stockés sur le serveur de l’application.
La dernière découverte de notre scan concerne les metrics de l’application. Ce fichier contient des informations cruciales sur le fonctionnement interne et les performances du système, comme les statistiques de performance, l’environnement, et des données de débogage. Ce fichier ne devrait pas être accessible publiquement.
Dans l’application testée, nous avons découvert des détails sur les capacités et les performances du serveur, ainsi que sur son fonctionnement.
Identification d’une vulnérabilité avec Nuclei
Dans ce deuxième scénario, nous allons voir comment Nuclei nous a permis d’identifier une vulnérabilité, conduisant à la découverte de plusieurs failles moyennes et importantes. L’exploitation de l’une d’elles a permis un accès direct aux fichiers du serveur via un « path traversal« .
Cette fois, nous avons utilisé l’application web https://google-gruyere.appspot.com. Cette app est volontairement vulnérable et utilisée pour sensibiliser et former à la cybersécurité.
Notre scan a révélé plusieurs vulnérabilités, la plupart menant à un accès au fichier /etc/passwd.

L’exploitation ici est plus simple et directe. Il a suffi de visiter l’une des URL identifiées pour constater l’accès au fichier /etc/passwd.
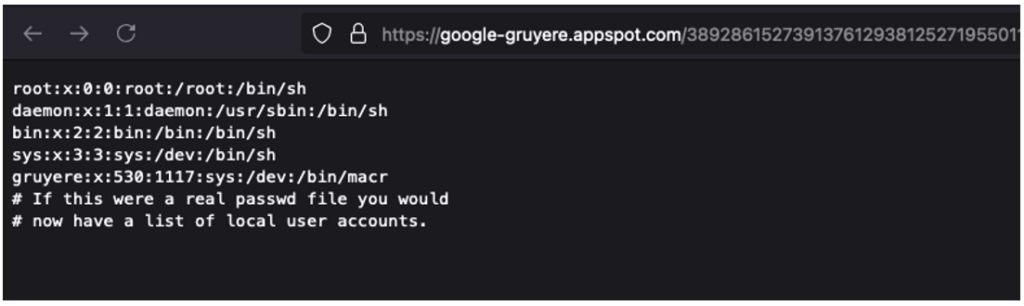
Ce fichier est souvent utilisé comme « proof of concept » car tous les utilisateurs ont généralement accès en lecture à ce fichier. Ainsi, cette vulnérabilité permet d’accéder directement aux fichiers du serveur sans authentification. Elle est considérée comme critique.
Bien que ce type de scénario soit rare lors de nos audits, il peut se produire et exposer nos clients à des conséquences graves.
Auteur : Théo ARCHIMBAUD – Pentester @Vaadata