Pour améliorer la rapidité d’affichage des pages web et alléger la charge des serveurs, de nombreuses entreprises s’appuient sur des mécanismes de mise en cache.
Ce système permet de stocker temporairement des ressources fréquemment sollicitées (comme des images, des scripts ou des pages HTML), afin de les servir plus rapidement lors de prochaines requêtes.
En plus de contribuer à une meilleure expérience utilisateur, la mise en cache joue également un rôle clé en SEO, puisqu’un temps de chargement optimisé peut influencer positivement le classement des pages dans les moteurs de recherche.
Cependant, pour exploiter pleinement les bénéfices du cache sans compromettre la sécurité, il est essentiel d’en comprendre le fonctionnement ainsi que les différents types existants.
Cette compréhension est d’autant plus importante que des failles mal exploitées dans la gestion du cache peuvent ouvrir la voie à des attaques redoutables, comme le web cache poisoning.
Guide complet sur le Web Cache Poisoning
Comment fonctionne le cache ?
Comme indiqué en préambule, le système de cache joue un rôle central dans l’optimisation des performances web. Il permet de stocker temporairement certaines ressources afin de limiter les appels redondants au serveur et d’accélérer l’affichage des pages.
On distingue principalement deux types de cache : le cache privé et le cache partagé :
- Le cache privé est propre à un utilisateur. Il est généralement stocké au niveau du navigateur et contient des éléments spécifiques à la session ou au profil de cet utilisateur. Ce type de cache ne doit jamais être partagé, car il peut contenir des informations sensibles.
- Le cache partagé, quant à lui, est utilisé pour stocker des contenus communs à plusieurs utilisateurs, comme les fichiers HTML statiques, les scripts JavaScript, les feuilles de style CSS ou les images. Ce cache peut être géré à différents niveaux de l’infrastructure, notamment via des proxies, des reverse proxies ou des réseaux de distribution de contenu (CDN). L’objectif est de réduire la charge sur les serveurs d’origine et d’accélérer la livraison des ressources à grande échelle.
C’est précisément ce cache partagé qui constitue la cible principale dans le cadre d’une attaque de type web cache poisoning. En effet, si un attaquant parvient à y injecter une réponse malveillante, celle-ci pourra être servie à de nombreux utilisateurs, amplifiant ainsi l’impact de l’attaque.
Il existe d’autres types de cache dans l’écosystème web : l’OPcache (pour l’exécution de scripts PHP) ou le cache de base de données. Ils ne seront pas abordés ici, car ils ne sont pas directement concernés par le web cache poisoning.
Enfin, il est important de rappeler que le cache est principalement utilisé pour des contenus statiques, c’est à dire des ressources identiques pour tous les utilisateurs. Toutefois, certaines techniques permettent de mettre en cache du contenu dynamique.
Comprendre le rôle des en-têtes HTTP dans la gestion du cache
Les en-têtes HTTP jouent un rôle essentiel dans la gestion du cache. Ils permettent aux différents acteurs impliqués dans le traitement d’une requête (navigateur, serveur, proxy, CDN…) de savoir comment stocker, valider ou rejeter une réponse. Parmi eux, le plus déterminant en matière de mise en cache est l’en-tête Cache-Control.
En-têtes Cache-Control et Age
Selon la RFC 9111, Cache-Control est utilisé pour spécifier les directives qui s’appliquent à tous les caches présents sur le chemin d’une requête ou d’une réponse.
Cet en-tête peut apparaître dans la réponse HTTP, pour indiquer comment la réponse doit être mise en cache, mais aussi dans la requête HTTP, pour indiquer comment le client souhaite que la réponse soit traitée par les caches intermédiaires.
Un autre en-tête utile est Age, qui indique depuis combien de temps une réponse est conservée en cache. Il est exprimé en secondes et permet de déterminer si une ressource est encore “fraîche” ou si elle est sur le point d’expirer.
Comprendre et manipuler ces en-têtes est essentiel pour qui veut sécuriser la gestion du cache ou pour un attaquant qui souhaite l’exploiter via une attaque de type web cache poisoning.
Prenons un exemple concret :
Cache-Control: max-age=604800
Age: 100Dans ce cas :
max-age=604800signifie que la réponse peut être considérée comme “fraîche” pendant 604 800 secondes (soit 7 jours).Age: 100indique que la réponse a déjà été stockée en cache depuis 100 secondes.
Cela signifie donc que le contenu est toujours valide et sera servi tel quel tant que le max-age n’est pas dépassé. Ce type d’information est crucial pour comprendre le comportement des caches et les opportunités potentielles pour les détourner.
Autres directives pouvant être rajoutées au Cache-Control
D’autres directives peuvent être ajoutées au Cache-Control pour en préciser le comportement, comme :
publicouprivate: pour indiquer si la ressource peut être partagée entre plusieurs utilisateurs.no-store: pour interdire tout stockage en cache.no-cache: pour obliger une validation auprès du serveur avant utilisation.must-revalidate,proxy-revalidate,s-maxage, etc.

Principes de la clé de cache
Le fonctionnement du cache repose sur un élément central : la clé de cache (cache key). Il s’agit d’un identifiant unique généré à partir des éléments d’une requête HTTP. Cette clé est construite en combinant différents paramètres comme :
- l’URL demandée,
- certains en-têtes HTTP (comme
Accept-Encoding,Host,User-Agent…), - voire des paramètres de requête, cookies ou éléments de session.
Fonctionnement côté serveur
Lorsqu’un serveur ou un proxy reçoit une requête, il génère une clé de cache correspondant à cette requête, puis vérifie si une réponse correspondante est déjà présente dans le cache. Si c’est le cas, la réponse en cache est immédiatement renvoyée au client, évitant ainsi une sollicitation inutile du serveur d’origine. On parle alors de cache hit.
Dans le cas contraire (cache miss), la ressource est récupérée depuis le serveur d’origine. Si cette ressource est jugée éligible à la mise en cache (selon les directives Cache-Control, Vary, ou d’autres règles de configuration), elle est ensuite stockée avec la clé générée, prête à être servie aux futures requêtes similaires.
Décryptage d’une configuration de cache
Prenons un exemple de configuration de cache avec Nginx :
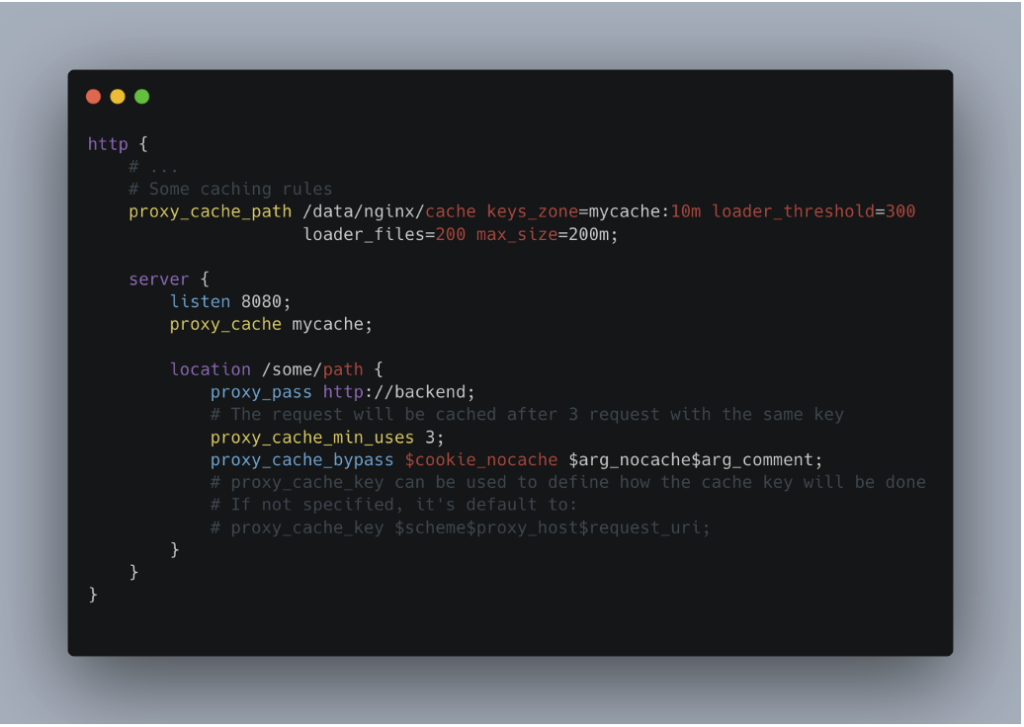
Décomposons maintenant cette configuration :
proxy_cache_path: Définit l’emplacement du cache sur le disque, les paramètres globaux comme la taille maximale des fichiers stockés, ainsi que la zone mémoire (par exemplemycache) utilisée pour gérer les clés de cache.proxy_cache: Active la mise en cache en précisant la zone mémoire à utiliser (mycache, ici).location /some/path: Spécifie que la configuration s’applique aux requêtes visant le chemin/some/path.proxy_pass: Indique l’URL du serveur en amont vers lequel les requêtes doivent être transmises (ici :http://backend).proxy_cache_min_uses: Définit le nombre minimum de requêtes avec la même clé avant que la réponse soit mise en cache. Cela permet d’éviter de stocker des contenus rarement demandés.proxy_cache_bypass: Permet de définir des conditions pour ignorer la mise en cache. Par exemple, si un cookienocache=trueest présent, la requête contournera le cache.proxy_cache_key: Spécifie la manière dont la clé de cache est générée. Par défaut, elle est basée sur$scheme$proxy_host$request_uri, mais elle peut être personnalisée pour inclure d’autres éléments (comme des en-têtes).
Dans cette configuration, les réponses du serveur backend sur le chemin /some/path ne seront mises en cache qu’après avoir été demandées au moins 3 fois avec la même clé (proxy_cache_min_uses 3).
Si une requête contient un cookie tel que nocache=true, elle bypassera le cache même si elle remplit les autres conditions. Une fois la réponse mise en cache, toutes les requêtes ultérieures partageant la même clé seront servies directement depuis le cache, sans solliciter à nouveau le backend.
Web Cache Poisoning et Web Cache Deception
Dans l’univers des failles liées au cache HTTP, on distingue principalement deux types d’attaques : le Web Cache Poisoning et le Web Cache Deception. Bien qu’elles reposent toutes deux sur des mécanismes similaires, à savoir l’exploitation d’un système de mise en cache mal configuré, leurs objectifs diffèrent sensiblement :
- Web Cache Deception
Cette attaque vise à tromper le système de cache pour qu’il stocke des réponses contenant des informations sensibles ou personnelles appartenant à un utilisateur authentifié. Une fois mises en cache, ces données peuvent ensuite être servies à d’autres utilisateurs non authentifiés accédant au même lien. Cela peut entraîner une exposition involontaire de données privées. Ce type d’attaque fera l’objet d’un article dédié. - Web Cache Poisoning
Ici, l’objectif est différent : l’attaquant cherche à injecter un contenu malveillant dans le cache, de manière à ce qu’il soit servi aux utilisateurs légitimes lors de leurs prochaines requêtes. L’attaque peut viser à injecter du JavaScript malveillant, rediriger l’utilisateur vers un site de phishing, ou fausser les réponses attendues.
Dans la suite de cet article, nous allons nous concentrer sur le Web Cache Poisoning, en explorant ses mécanismes, ses vecteurs d’attaque, et des exemples concrets permettant d’en comprendre l’impact.
En quoi consiste une attaque Web Cache Poisoning ?
Fonctionnement du Web Cache Poisoning
Pour qu’une attaque de Web Cache Poisoning soit possible, plusieurs conditions préalables doivent être réunies.
Le principe repose sur une manipulation subtile du système de cache en exploitant des écarts entre les éléments qui influencent la réponse du serveur et ceux qui composent la clé de cache.
En premier lieu, et cela peut sembler évident, la ressource ciblée doit être mise en cache et surtout de manière publique (c’est-à-dire partagée entre plusieurs utilisateurs).
Pour le vérifier, on peut analyser les en-têtes de réponse HTTP, notamment Cache-Control, qui donnent souvent des indices sur les politiques de cache appliquées. Il est toutefois important de noter qu’une réponse peut être servie depuis le cache sans qu’aucun en-tête ne l’indique explicitement.
Le deuxième point crucial consiste à identifier un élément influent non inclus dans la clé de cache. En effet, il faut trouver un paramètre de la requête (souvent un en-tête HTTP, comme X-Forwarded-Host ou User-Agent) qui modifie la réponse du serveur, sans que ce dernier soit pris en compte dans la génération de la clé de cache.
Ainsi, si un attaquant réussit à faire stocker une réponse modifiée (par exemple, contenant un script malveillant), cette version sera servie à tous les utilisateurs dont la requête correspond à la même clé de cache ; même s’ils n’ont pas transmis l’en-tête malveillant.
La troisième étape sera d’analyser comment l’élément injecté influe sur la réponse. Est-il reflété dans le corps de la réponse ? Est-il affiché tel quel ou passé par un processus de validation ? Provoque-t-il une erreur, une redirection, un comportement anormal ?
En fonction de la dernière étape, cela nous amènera à différents types de vulnérabilités.
Impacts d’une attaque Web Cache Poisoning
Une attaque réussie de Web Cache Poisoning peut avoir des répercussions sévères sur les utilisateurs et sur l’organisation visée.
Lors de nos tests d’intrusion d’applications web, nous rencontrons généralement deux types de scénarios :
XSS stockée via le cache
Dans ce cas, l’attaquant parvient à injecter un payload XSS qui est reflétée dans la réponse sans être correctement filtrée ou échappée.
Puisque cette réponse est ensuite mise en cache, chaque utilisateur accédant à cette ressource via le cache se voit servir le contenu malveillant.
Ce type d’attaque peut permettre le détournement de sessions, le vol de comptes, l’exfiltration de données sensibles, etc.
Cache-Poisoned DoS
Le Cache Poisoned Denial of Service (DoS) se produit lorsqu’un élément non inclus dans la clé de cache entraîne une erreur côté serveur.
Cette erreur est alors mémorisée par le cache, et toutes les requêtes suivantes recevront la même réponse erronée, tant que le cache reste valide.
Cela peut provoquer une indisponibilité partielle ou totale du service pour les utilisateurs, des pertes financières, une dégradation de l’image de marque, etc.
Les moyens d’induire ce type d’erreur sont variés : injection de headers malformés, surcharge d’un paramètre attendu, altération du comportement de routage, etc. Plusieurs de ces techniques sont bien documentées et peuvent être reproduites à des fins de test.
Exemple de XSS stockée via Cache Poisoning
Pour illustrer une attaque de cache poisoning menant à une XSS stockée, prenons le cas d’une application web qui utilise la valeur du header X-Forwarded-Host pour déterminer l’emplacement de ses fichiers JavaScript statiques.
Cette configuration devient problématique dès lors que l’application n’effectue aucun contrôle sur ce header, permettant à un utilisateur malveillant d’en modifier la valeur.
Le comportement vulnérable vient du fait que l’application se fie à une donnée issue de la requête HTTP de l’utilisateur, sans vérification ni filtrage, pour construire une réponse qui sera ensuite mise en cache.
Avant toute tentative d’exploitation, il convient de vérifier si l’application utilise un mécanisme de cache.
Cela peut être déterminé en observant les en-têtes HTTP (headers) de la réponse :
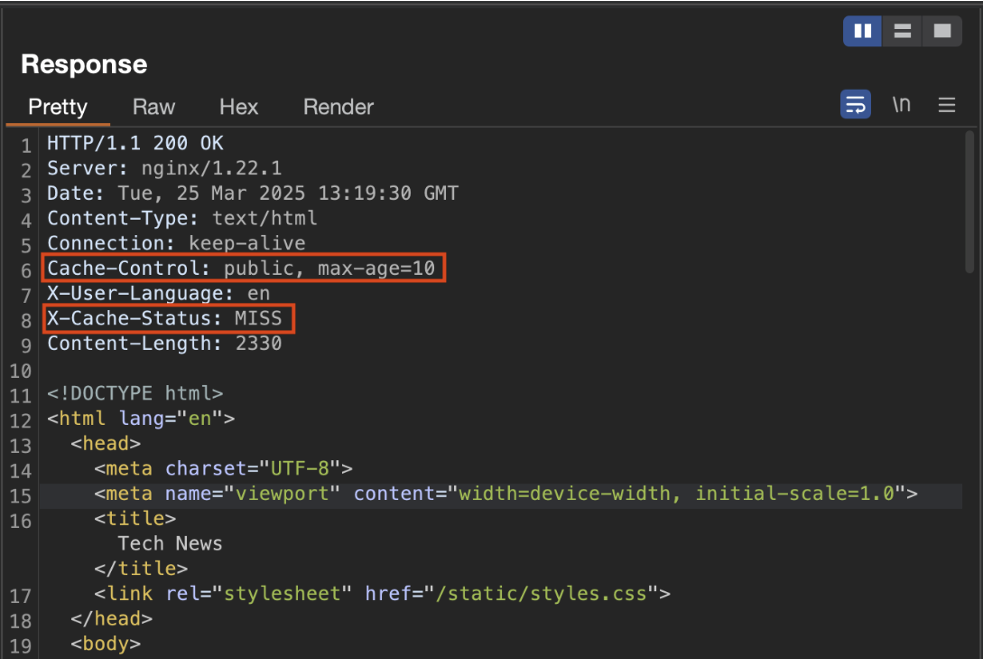
Analyse des headers de réponse
L’analyse des headers HTTP permet d’obtenir plusieurs informations clés sur le comportement du cache :
Cache-Controlcontient ici deux directives :publicetmax-age=10.- La directive
publicsignifie que la réponse peut être partagée entre plusieurs utilisateurs via un cache intermédiaire. max-age=10indique que le contenu mis en cache ne sera valable que pendant 10 secondes. Passé ce délai, une nouvelle requête devra être envoyée au serveur d’origine pour obtenir une réponse fraîche.- Ce header est systématiquement présent, car il détermine la politique de mise en cache de la ressource.
- La directive
X-Cache-Statusest un header utilisé principalement pour le débogage.- Lorsqu’il affiche
MISS, cela signifie que la réponse a été générée directement par le serveur backend. - S’il affiche
HIT, cela indique que la réponse a été servie depuis le cache. - Ce header n’est pas toujours présent, car il est optionnel et dépend de la configuration du système de cache.
- Lorsqu’il affiche
- Enfin, la présence de NGINX dans les headers permet de déduire quel serveur traite les requêtes. Ici, NGINX est responsable de la gestion du cache. Par défaut, il utilise une clé de cache construite à partir de la variable
$scheme$proxy_host$request_uri, c’est-à-dire le protocole, l’hôte du proxy, et l’URI de la requête.
Après une première requête, si l’on répète la même demande, le header X-Cache-Status affiche maintenant HIT, indiquant que la réponse a bien été stockée et servie depuis le cache.
Toutefois, la mise en cache n’est pas systématique dès la deuxième requête. Cela dépend de la configuration précise du serveur et des politiques de cache appliquées.
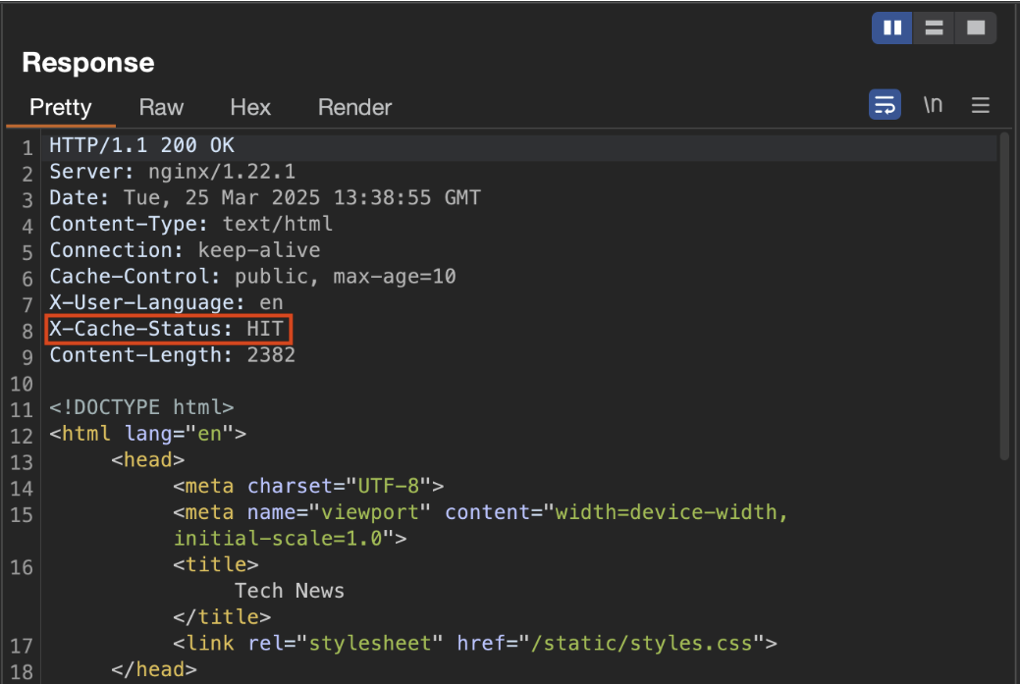
Injection via le header X-Forwarded-Host et détournement du cache
En ajoutant manuellement le header X-Forwarded-Host dans une requête, avec une valeur pointant vers un serveur que nous contrôlons, et en s’assurant que la réponse provient bien du serveur (c’est-à-dire avec un X-Cache-Status à MISS), on peut observer que le contenu de la réponse est modifié, et le fichier /static/script.js est désormais chargé depuis notre propre adresse :

Nous constatons d’ailleurs que notre serveur reçoit bien une requête vers ce fichier. Le point crucial ici est que X-Forwarded-Host ne fait pas partie de la clé de cache. Cela signifie que même si ce header est utilisé pour construire dynamiquement l’URL du script, il n’est pas pris en compte pour déterminer l’unicité de la réponse mise en cache.
En conséquence, la réponse contenant le lien vers notre script externe est éligible à la mise en cache et pourra être servie à tous les utilisateurs dont les requêtes correspondent à cette même clé (c’est-à-dire, sans tenir compte du header injecté).
Puisque nous contrôlons maintenant la source du script, il devient trivial d’y insérer du code malveillant. Le navigateur des utilisateurs chargera ainsi un script contenant un payload XSS. On est donc face à une attaque de type XSS stockée, avec une persistance limitée à la durée définie par max-age.
Un attaquant pourrait facilement automatiser cette démarche afin d’injecter à intervalles réguliers un script malveillant dans le cache, assurant ainsi que toute personne accédant à la ressource reçoive une version compromise.
Comment prévenir les attaques de type Web Cache Poisoning ?
Nous avons vu comment fonctionne le cache, de quelle manière une attaque de cache poisoning peut être exploitée, ainsi que les conséquences possibles. Il est désormais essentiel de s’intéresser aux bonnes pratiques à mettre en place pour se prémunir contre ce type d’attaque.
Protéger un système contre le cache poisoning peut s’avérer complexe, car les interactions avec le cache ne sont pas toujours évidentes à analyser. Néanmoins, plusieurs approches permettent de réduire considérablement les risques :
Désactiver le cache
C’est la solution la plus radicale, mais aussi la plus efficace. En désactivant complètement la mise en cache, on supprime de facto la surface d’attaque.
Cela peut toutefois engendrer une dégradation des performances, et doit donc être envisagé en fonction des besoins réels de l’application.
Bien configurer les règles de cache
Une alternative plus fine consiste à maîtriser précisément les règles de cache. Il est crucial de déterminer quelles ressources peuvent être mises en cache et lesquelles ne le doivent pas.
Les contenus dynamiques ou personnalisés ne devraient en aucun cas être partagés via le cache. À l’inverse, les contenus statiques ou publics peuvent y être éligibles.
Intégrer certains headers HTTP dans la clé de cache
Certains headers HTTP, comme X-Forwarded-Host, Accept-Encoding ou User-Agent, peuvent influencer la réponse du serveur.
Si ces headers ne sont pas pris en compte dans la génération de la clé de cache, il devient possible pour un attaquant de manipuler la réponse sans que le cache n’en tienne compte. Il est donc impératif de les inclure explicitement dans la clé de cache si leur valeur influe sur la réponse.
Limiter le cache aux fichiers statiques
Dans la mesure du possible, la mise en cache doit être réservée aux fichiers statiques : images, fichiers JavaScript, feuilles de style CSS, polices, etc.
Ces ressources ne changent pas en fonction de l’utilisateur, ce qui réduit considérablement les risques de manipulation.
Valider rigoureusement les entrées utilisateur
Enfin, une validation stricte des entrées utilisateur est essentielle. Même si une faille de cache est identifiée, une validation correcte permet souvent de bloquer l’injection de contenu malveillant, comme dans le cas d’une tentative de XSS.
Cela passe par la vérification du type, de la longueur, du format et de la présence de caractères spéciaux dans les champs d’entrée.
Auteur : Théo ARCHIMBAUD – Pentester @Vaadata